
BAB I - fanmooy.files.wordpress.com file · Web viewFase kedua ialah statistika induktif adalah...
26
STATISTIKA DASAR Toward Statistical Inference Kelompok 8 (non reguler) : Hafiz Farihi (3115076798) Fani Khadijah (3115076773) Siti Widiyati (3115076788) Andika Purnamasari (3115076790)
Transcript of BAB I - fanmooy.files.wordpress.com file · Web viewFase kedua ialah statistika induktif adalah...

STATISTIKA DASARToward Statistical Inference
Kelompok 8 (non reguler) :
Hafiz Farihi (3115076798)
Fani Khadijah (3115076773)
Siti Widiyati (3115076788)
Andika Purnamasari (3115076790)
Jurusan Pendidikan Matematika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Negeri Jakarta
2008

DAFTAR ISI
Daftar Isi…………………………………………………………………………….2
BAB I PENDAHULUAN…………………………………………………………..3
BAB II PEMBAHASAN…………………………………………………………...4
A. Pengertian Sampel dan Kegunaannya.......................................................4
B. Contoh Sampel..........................................................................................4
C. Pengambilan Sampel.................................................................................6
D. Soal-soal Latihan.....................................................................................14
DAFTAR PUSTAKA
2

BAB I
PENDAHULUAN
Statistika terbagi atas 2 fase, yaitu statistika deskriptif dan statistika induktif. fase
pertama dikerjakan untuk melakukan fase kedua. Fase kedua ialah statistika induktif
adalah statistik yang digunakan untuk menyimpulkan data-data statistik. Statistika
induktif menyimpulkan data-data statistik (toward statistical inference) yang berupa
karakteristik populasi.
Populasi ialah totalitas semua nilai yang mungkin, baik hasil menghitung
maupun pengukuran, kuantitatif,ataupun kualitatif, dan pada karakteristik tertentu
mengenai sekumpulan objek yang lengkap dan jelas.
Contoh populasi :
1. Semua kupu-kupu di pegunungan Rocky
2. Seluruh mahasiswa di Universitas Negeri Jakarta
Karena jumlah populasi takterhingga maka untuk mendapatkan data-data statistic
dan mengambil kesimpulan statistic dengan mudah digunakanlah sample. Sample
tersebut diambil dari populasi yang bersangkutan.
3

BAB II
PEMBAHASAN
A. Pengertian Sampel dan KegunaannyaDalam belajar statistika, situasi dibagi menjadi 2, yaitu apa yang kita ingin
ketahui dan apa yang kita ketahui. Kedua hal ini bukan konsep yan susah dan kedua hal
ini sangat penting. Populasi adalah total keseluruhan elemen – elemen yang menjadi
perhatian dalam suatu penelitian/pengamatan. Sampel adalah kumpulan elemen/bagian
dari populasi yang diteliti.
Contoh Populasi:
1. Semua bencana alam yang pernah terjadi di Indonesia
2. Semua gadis yang berambut panjang di UNJ
Contoh Sample:
1. 10 bencana alam terparah di Indonesia
2. Gadis yang berambut panjang di Fakultas Ekonomi
Sample adalah bagian simpel dari populasi. dalam menentukan populasi ada cara
praktis untuk meringkas. Biasanya kita membutuhkan dana atau waktu yang banyak
dalam meneliti suatu populasi.
Karena informasi dari sample akan menunjukkan kesimpulan dari populasi, maka
hal ini sangatlah penting yang dimana sample mencerminkan keadaan populasi.
Idealnya sample yang ada secara tepat menggambarkan populasi dalam setiap hal
sehingga fakta yang ada dari sample secara akurat menggambarkan populasi yang
besar. Ketika sample tidak dapat menggambarkan populasi dengan layak, kesalahan
dapat terjadi dengan mudah. Dan ini dinamakan bad sample (sample buruk).
B. Contoh sampel 1. Sampel yang buruk ( bad sample )
Tim bola basket digunakan sebagai sampel untuk mempelajari tinggi dari
murid SMA. Akibatnya sampelnya akan tertutup dengan murid yang lebih
4

tinggi dari yang sebenarnya karena pemain basket lebih tinggi dari rata-
rata kita.
10 dari teman terbaik digunakan untuk memprediksi pemenang dari
pemilihan. Akibatnya karena cenderung memilih teman yang yakin
dengan gambaran kita , sampel ini akan cenderung sewajarnya pilihan
dibanding mendapatkan keakuratan petunjuk dari hasil terbaik pemilihan.
Masalah bias
Hal umum yang digunakan untuk menggambarkan masalah yang digunakan ketika
sampel tidak bagus dari suatu populasi adalah bias.
Ada 2 sumber yang dugunakan dalam penelitian survey pertama adalah seleksi bias
dimana hal itu adalah perbedaan sistematik antara populasi dan sampel. Intinya bias
harus di buat sekecil mungkin. Sumber kedua masalah dari pengantar survey yaitu
respon bias, seharusnya menurut kenyataan tidak setiap orang yang diketahui akan
mengmbalikan pertanyaan survey.
Contoh soal: Mengambil sampel direktur marketing dari sebuah firma kecil dengan
membuka buku telepon dengan menutup mata. Kemudian 30 nama telah terpilih. 30
orang tersebut memiliki nama belakang Johnson yang termasuk didalamnya 2
Gertrudes, 4 Gilbert, 4 Glens, 4 Gordon, 6 Gregory, dan 4 Gunnars.
a) Apakah soal di atas merupakan sample yang representative untuk
populasi sebuah kota?
b) Apakah soal di atas merupakan sample yang bias?
c) Apakah soal di atas memungkinkan anggota dari sample tidak
independen?
Jawab:
a) tidak, soal diatas bukan sampel yang representative untuk populasi
sebuah kota
b) ya, sample diatas merupakan sample yang bias
c) ya, anggota sample tersebut tidak independent.
5

2. Sampel yang Baik ( Good Sample )
368 perusahaan yang mengembalikan questioner (dari 500 quesioner yag
dikeluaran)
53 gempa bumi terhebat 15 tahun terakhir di Indonesia.
C. Pengambilan sample1. Sampel Acak
Sample acak adalah salah satu cara yang paling baik untuk memilih sample untuk
tujuan statistika. Sampling acak membantu meyakinkan bahwa sample menggambarkan
seluruh populasi dan tidak bias pada sebagian populasi.
Sifat sampel acak:
a. tanpa bias, yaitu setiap unit mempunyai peluang yang sama untuk terpilih
b. indepensi , yaitu pemilihan sebuah unit tigak mempengaruhi unit lainnya.
Secara singkat, sample acak harus memenuhi dua syarat:
1. Setiap anggota dari populasi mempunyai kesempatan yang sama untuk
jadi sample.
2. Anggota sample dipilih secara bebas tanpa memperhatikan satu sama lain.
Syarat pertama penting untuk meyakinkan bahwa semua anggota populasi
mempunyai kedudukan yang sama. Ini merupakan jaminan bahwa tidak akan ada
diskriminasi dalam populasi. Syarat yang kedua dibutuhkan untuk meyakinkan bahwa
semua sample memiliki kedudukan yang sama.
Untuk melihat mengapa syarat kedua dibutuhkan, perhatikan sample berikut yang
memenuhi syarat pertama tapi tidak memenuhi syarat yang kedua.
Contoh sampel tak acak:
Dari 100 orang bekulit putih dan 100 orang berkulit hitam, hanya dipilih atau
sampel yang diambil 15 orang yang berkulit putih / 15 orang berkulit hitam, sehingga
pilihan dari hitam atau putih sama.
Meskipun secara individual masing-masing unit dari populasi mempunyai
kesempatan yang sama untuk menjadi sample, mengambil kolektif sdample adalah
tidak adil dan tidak acak karena masing-masing sample pasti putih atau hitam dan itu
6

tidak akurat menggambarkan populasi dari 200 orang yang terdiri dari campuran kedua
kelompok.
Tidak adanya kebebasan pada contoh ini mungkin terlihat dari fakta bahwa jika
orang yang pertama dari sample adalah hitam, maka yang kedua dan seterusnya juga
akan hitam. Karena sample dipilih dari anggota yang dapat diprediksi dari yang
lainnya, maka akan ada ketergantungan satu sama lain. Jadi kebebasan yang diperlukan
untuk sample acak gagal dilakukan dalam kasus ini.
Contoh sampel acak:
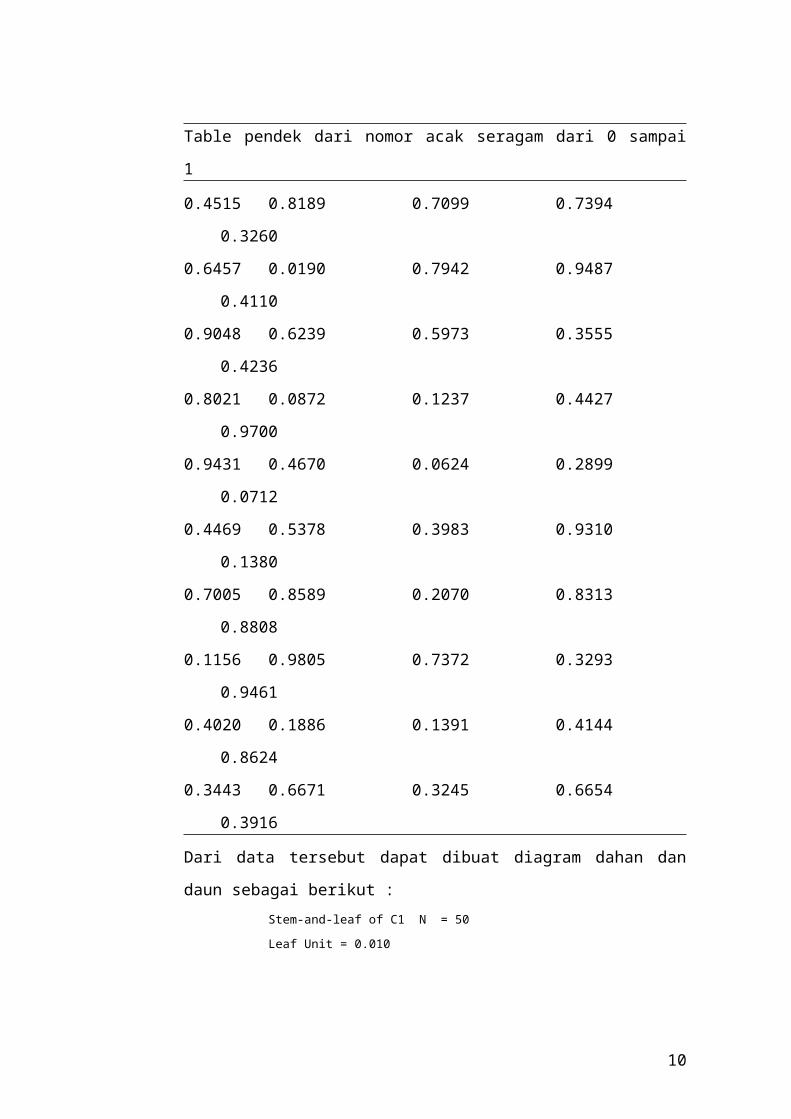
Table pendek dari nomor acak seragam dari 0 sampai 1
0.4515 0.8189 0.7099 0.7394 0.3260
0.6457 0.0190 0.7942 0.9487 0.4110
0.9048 0.6239 0.5973 0.3555 0.4236
0.8021 0.0872 0.1237 0.4427 0.9700
0.9431 0.4670 0.0624 0.2899 0.0712
0.4469 0.5378 0.3983 0.9310 0.1380
0.7005 0.8589 0.2070 0.8313 0.8808
0.1156 0.9805 0.7372 0.3293 0.9461
0.4020 0.1886 0.1391 0.4144 0.8624
0.3443 0.6671 0.3245 0.6654 0.3916
Dari data tersebut dapat dibuat diagram dahan dan daun sebagai berikut :Stem-and-leaf of C1 N = 50
Leaf Unit = 0.010
4 0 1678
9 1 12338
11 2 08
18 3 2224599
(8) 4 01124456
24 5 39
22 6 2466
18 7 00399
13 8 013568
7 9 0344478
7

Untuk memilih sample acak untuk 10 orang dari kelompok yang terdiri dari 83
orang dan memenuhi syarat untuk berpartisipasi penelitian, prosesnya adalah sebagai
berikut:
1) Langkah pertama, Lebelkan setiap orang dengan nomer
dari 1 sampai 83
2) Kedua, pilih nomer secara acak yang ada pada table,
misalnya nomor acak pertama adalah 0.8021
3) Kalikan nomor acak tersebut dengan ukuran populasi
0.8021 x 83 = 66.57
4) Tambahkan 1 dan bulatkan hasilnya
(66.57 + 1) = 67.57 → 67
5) Orang ke 67 termasuk kedalam sample
6) Ulangi langkah ke 3 sampai langkah ke 6 sampai
mendapatkan 10 orang berbeda yang dipilih untuk sample
0.0872 x 83 = 7.24 (7.24 + 1) = 8.24 → 8
Orang ke 8 termasuk kedalam sample
0.1237 x 83 = 10.27 (10.27 + 1) = 11.27 → 11
Orang ke 11 termasuk kedalam sample
0.4427 x 83 = 36.74 (36.74 + 1) = 37.74 → 37
Orang ke 37 termasuk kedalam sample
0.9700 x 83 = 80.51 (80.51 + 1) = 81.51 → 81
Orang ke 81 termasuk kedalam sample
0.9431 x 83 = 78.28 (78.28 + 1) = 79.28 → 79
Orang ke 79 termasuk kedalam sample
0.4670 x 83 = 38.76 (38.76 + 1) = 39.76 → 39
Orang ke 39 termasuk kedalam sample
0.0624 x 83 = 5.18 (5.18 + 1) = 6.18 → 6
Orang ke 6 termasuk kedalam sample
0.2899 x 83 = 24.06 (24.06 + 1) = 25.06 → 25
Orang ke 25 termasuk kedalam sample
0.4469 x 83 = 37.09 (37.09+ 1) = 38.09 → 38
8

Orang ke 38 termasuk kedalam sample
Sample akhirnya adalah orang ke 67, 8, 11, 37, 81, 79, 39, 6, 25, dan 38.
2. Parameter Populasi
Banyaknya pengamatan dalam populasi dinamakan ukuran populasi.
Menaksirkan beberapa nilai populasi ( parameter populasi ) dapat dilakukan dengan
menggunakan sampel dari populasi. Dan nilai sampel digunakan untuk menaksir nilai
sampel statistik.
Contoh dari rataan sampel dan rataan populasi
Berikut ini ada 2 contoh untuk mengilustrasikan perbedaan antara rataan sampel
dan rataan populasi :
a. Untuk mempelajari tinggi dari pelajar SMA dengan menggunakan sampel
acak 589 pelajar. Rataan sampel dari 589 dapat dihitung dari 5 kaki samapi
5,8 kaki. Rataan dari seluruh populasi semua pelajar SMA tidak dapat
diketahui. Bagaimanapun rataan dapat lebih dahulu diikuti. Jka tinggi setiap
pelajar SMA dapat diukur melalui rataan populasi yaitu, rataan sampel yang
kurang lebih dari 14 juta data.
b. Seorang kandidat kantor politik menjabat atas pemberian suara. Perhitungan
akhir untuk sampel random dari 1508 pemilih, menunjukkan 58,2% dari
orang-orang tersebut untuk memilih kandidat. Persentase ini berpengaruh
pada rataan sampel dari jawaban (yang dibicarakan adalah jawaban ya /
tidak). Rata-rata dari seluruh populasi yang terdaftar pemilih tidak diketahui
oleh siapapun. Meskipun nilai tersebut tidak diketahui, namun rata-rata
tersebut memiliki pengertian jika diinterprestasikan semua pemilih dan
mereka mengatakan siapa yang mereka maksud untuk dipilih, maka akhirnya
prsentasi akan ada rata-rata populasiya.
3. Standar Error dari rataan
Variable dari nilai rata-rata dihitung dari sample acak yang merupakan ukuran
dari kuantitas yang disebut standar error dari rataan . rataan adalah kuantitas acak yang
9
merefleksikan dasar pengacakan pada pemilihan dari sample acak. Variabel tersebut
dapat dihitung dengan menggunakan standar deviasi dari sampel. Rataan
mengkombinasikan seluruh nilai data mengubahnya menjadi variabel sesedikit
mungkin dari pada banyak nilai data. Dan rataan merupakan variable sesedikit mungkin
yang ditentukan oleh teorema limit pusat.
Nilai populasi yang benar menggunakan teorema limit pusat untuk mensibtusikan
taksiran sample. Standar error rataan dihitung dengan membagi standar deviasi dengan
banyaknya nilai data
Standar Error Rataan =
=
Contoh standard error dari rataan:
Gunakan data berikut unutk menghitung standard error dari rataan sampel
Rataan sampel = 250
Standar deviasi sempel = 36
n sampel = 16
jawab:
standard error rataan =
= 9
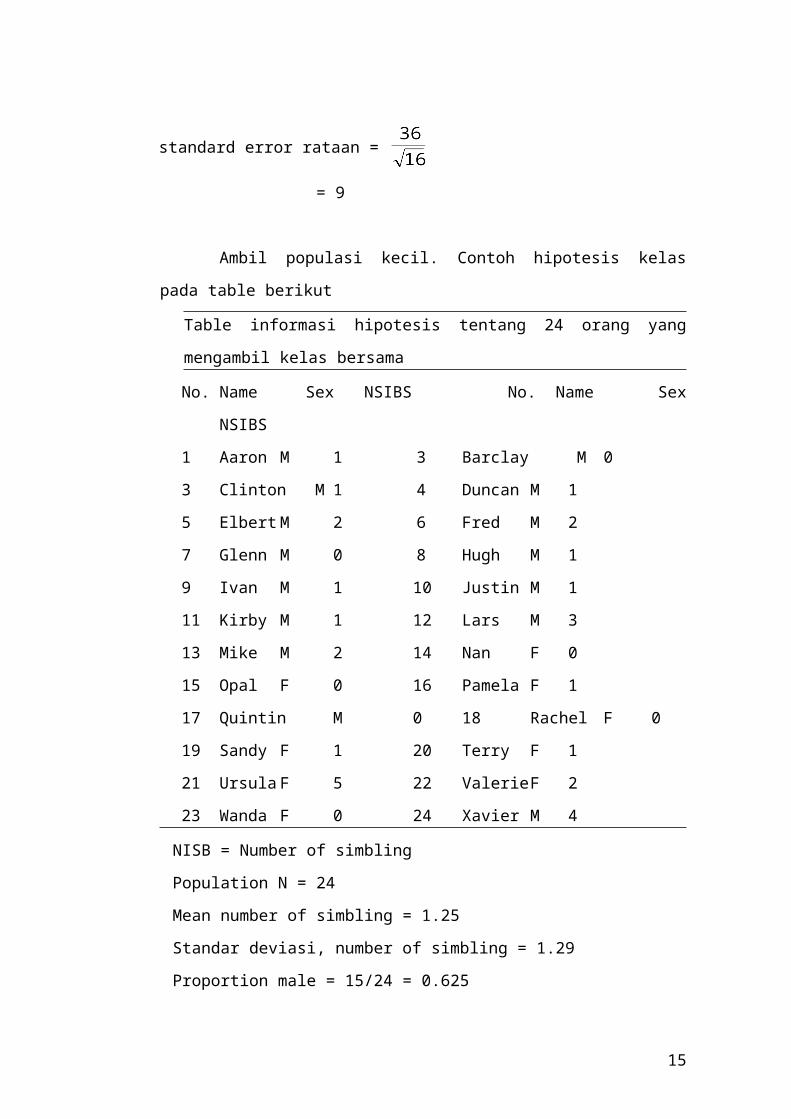
Ambil populasi kecil. Contoh hipotesis kelas pada table berikut
Table informasi hipotesis tentang 24 orang yang mengambil kelas bersama
No. Name Sex NSIBS No. Name Sex NSIBS
1 Aaron M 1 3 Barclay M 0
3 Clinton M 1 4 Duncan M 1
5 Elbert M 2 6 Fred M 2
7 Glenn M 0 8 Hugh M 1
9 Ivan M 1 10 Justin M 1
11 Kirby M 1 12 Lars M 3
10

13 Mike M 2 14 Nan F 0
15 Opal F 0 16 Pamela F 1
17 Quintin M 0 18 Rachel F 0
19 Sandy F 1 20 Terry F 1
21 Ursula F 5 22 Valerie F 2
23 Wanda F 0 24 Xavier M 4
NISB = Number of simbling
Population N = 24
Mean number of simbling = 1.25
Standar deviasi, number of simbling = 1.29
Proportion male = 15/24 = 0.625
Dari Tabel diatas dapat diketahui bahwa hanya terdapat 24 anggota dalam kelas
tersebut atau yang dapat disebut dengan populasi, namun populasinya berupa populasi
kecil. Dari populasi tersebut dapat diketahui meannya yaitu 0.625 dan standar
deviasinya 1.29 dan standar errornya seharusnya 0. perhitungannya
Standard error =
Perhitungan standar eror tersebut untuk sample acak dari 24 anggota untuk
populasi yang lebih banyak dan luas. Sedangkan jika 24 anggota tersebut merupakan
populasi sebenarnya maka perlu digunakan koreksi factor.
Koreksi faktor =
Dimana n adalah ukuran sample dan N adalah ukuran populasi. Untuk
mendapatan standar eror yang benar nilai dari rumus umum harus dikalikan dengan
koreksi factor.
Koreksi Standar Error =
Jika sampel sebenarnya segala populasi, kemudian factor koreksi menghasilkan 0.
11

Ketika standard error dikalikan dengan yang diatas, maka standard error yang
benar adalah 0. Ini yang kita sebut situasi yang diketahui nilai populasinya ketika
sampel bagian terkecil dari populasi, n/N mendekati 0 dan kita dapat
Kita kalikan standard error umum dengan yang diatas, maka kita akan
mendapatkan nilai yang sama ketika kita memulainya.
4.Standard error dari proporsi
Perhitungan standard error dari proporsi menggunakan metode langsung
1) Mengurangi 1 dengan proporsi
2) Kalikan dengan proporsi itu sendiri
3) Bagi dengan ukuran sampel dengan 1
4) Ambil akarnya
Rumusnya:
Standard error of proportion =
Contoh standard error dari populasi:
Pada kolom iklan di bagian bisnis dari New York Time suatu waktu
mendiskusikan kampanye periklanan yang didasari dengan tes rasa dari dua “jenis
nama premium” dari ayam. Dari 371 responden yang menerima ayam di rumah, 197
menunjukkan bahwa mereka memilih jenis “cookin good” setelah dibandingkan dengan
jenis yang berbeda (yang lebih terkenal). Proporsinya 197/371 = 0,531 mennjukkan
bahwa sampel ini 0,531 atau 53,1% memilih jenis “cookin good”.
Jadi, perhitungannya sebagai berikut:
a. temukan standard deviasi
standard deviasi =
=
12

= 0,49971
b. kemudian berdasarkan hasil di atas temukan standard error dari proporsi
standard error =
=
= 0,02594
c. atau gunakan metode perhitungan
standard error =
=
=
= 0,2594
Bagian dari sampel yang memilih jenis “cookin good” bisa sebesar 0.531 atau
sebesar 0.02594 ke bawah atau ke atas. Maka standar errornya bisa jadi lebih dari atau
kurang dari 0.531. Dengan standar error 0.02594, maka semua nilai di antara 0.531-
0.02594 = 0.5051 sampai 0.531 + 0.02594 = 0.5569 bisa menjadi proporsi yang tepat
dari sampel.
D. Soal-soal Latihan
1. anggap direktur marketing dari sebuah firma kecil memilih sample dengan
membuka buku telepon dengan menutup mata. Kemudian ada 30 orang yang nama
13

keluarganya Johson diantaranya 4 Gertrudes, 4 Gilberts, 4 Glens, 4 Gordons, 6
Gregorys, 4 Gunnars.
a. Apakah ini menggambarkan sample dari populasi kota?
b. Apakah ini bias sample?
c. Apakah ini termasuk sample tidak acak?
2. Anggap Anda mempunyai populasi sebanyak 100 orang. Anda menomeri dari 1-
100. Anda menggambarkan sample acak dan nilai acak antara 0 dan 1 adalah .490.
Orang yang mana yang akan dipilih sebagai sample?
3. Anggap Anda akan menggambar sample acak dari populasi yang diberikan. Anda
sudah punya daftar dan Anda mendapatkan lima nomer acak berurutan antara 0-1.
.9749 .9811 .8771 .0997 .7841
No Nama Jenis Kelamin NSIBS No Nama Jenis Kelamin NISBS
1. Aaron L 1 2 Barclay L
3 Clinton L 1 4 Duncan L
5 Elbert L 2 6 Fred L
7 Glenn L 0 8 Hugh L
9 Ivar L 1 10 Justin L
11 Kirbi L 1 12 Lars L
13 Mike L 2 14 Nan P
15 Opal P 0 16 Pamela P
17 Quintin L 0 18 Rachel P
19 Sandy P 1 20 Terry P
21 Ursula P 5 22 Valene P
23 Wanda P 0 24 Xavier L
a. Ubahlah
menjadi integer (seluruh nilai) dari 1-24
b. Apa anggota
dari kelas tersebut yang menjadi sample?
c. Berapa
nilai rataan dari orang tersebut?
14
4. Gunakan data ini untuk menghitung standard error dari rataan sample.
a.Rataan sample = 250, simpangan baku = 36, n = 16
b. Rataan sample = 250, simpangan baku = 36, n = 81
c.Rataan sample = 250, simpangan baku = 36, n = 144
5. Anggap Anda mengambil sample acak dari 4 orang di dalam kelas dan menanyakan
kepada mereka berapa banyak saudara kandung yang mereka punya.
Kirby 1
Lars 3
Wanda 0
Hugh 1
a. Berapa rataan sample?
b. Berapa simpangan baku dari sample?
c. Berapa standard error dari rataan populasi?
1. Berapakah galat (standar error) dari proporsi jika proporsi sampel 0.45 dan ukuran
sampel 25?
2. Misalkan kita mengambil empat sampel acak dari sebuah kelas dan mendata jenis
kelamin mereka. Dari pengambilan sampel tadi kita dapatkan hasil:
Azizah P Syamsul L Badriah P
Sutrisno L Aisyah P
a. Berapakah proporsi sampel dari laki-laki?
b. Berapakah standar error dari proporsi laki-laki?
c. Berapakah perkiraan jumlah laki-laki di kelas itu?
Jawaban
1. a. Sample tidak menggambarkan keadaan populasi kota.
b. Ya, ini seperti bias sample
c. Ini termasuk sample acak.
2. Yang akan menjadi sample = .490 x 100 = 49.
(49 + 1) = 50
jadi, yang terpilih sebagai sample adalah orang yang ke 50.
15

3. a. Ubah ke dalam bentuk integer menjadi:
(.9749 x 24) + 1 = 23.39 + 1 = 24.39 mendekati 24
(.9811 x 24) + 1 = 23.55 + 1 = 24.55 mendekati 24
(.8771 x 24) + 1 = 21.05 + 1 = 22.05 mendekati 22
(.0997 x 24) + 1 = 2.392 + 1 = 3.392 mendekati 3
(.7841 x 24) + 1 = 18.81 + 1 = 19.81 mendekati 19
b. Anggota sample dalam kelas : 3 (Clinton), 19 (Sandy), 22(valene),
24(Xavier)
c. Nilai rataan sample dari saudara kandung
4. a. Standard error dari rataan =
=
= 9
b. Standard error dari rataan =
=
= 4
c. Standard error dari rataan =
=
= 3
5. a. Rataan sample =
=
= 1.25
b. Simpangan baku =
16

=
=
=
=
= 1.0897
c. Standard error dari rataan =
= .54485
6.
7.
a. Proporsi laki-laki:
17

b. Standar error dari proporsi laki-laki:
c. Perkiraan jumlah laki-laki di kelas itu:
Karena nilai galat dari proporsi laki-laki adalah 0.245 berarti perkiraan
julmlah laki-laki di kelas itu adalah diantara 0.4 - 0.245 = 0.155 dan 0.4 +
0.245 = 0.645
DAFTAR PUSTAKA
Siegel, Andrew F dan Charles J.__. Morgan. Statistics and Data Analysis An
Introduction._____
18

19


















