
Analisis Regresi Logistik Dengan Minitab
15
ANALISIS DATA KATEGORI Regresi Logit Dosen Pengampu : Eni Sumarminingsih SSi, MM. Kelompok : 1. Danny Prasetyo Hartanto (0810950034) 2. Mahardika Dwi Jayanti (0810950050) 3. Sabrina Yunitasari (0810950064) 4. Efrida Dwi Candrawati (0810953034) 5. Meirizal Dwi Ebtiyanto (0810953046) PRODI STATISTIKA JURUSAN MATEMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS BRAWIJAYA MALANG 2011
-
Upload
0810950064 -
Category
Documents
-
view
1.198 -
download
107
Transcript of Analisis Regresi Logistik Dengan Minitab

ANALISIS DATA KATEGORI
Regresi LogitDosen Pengampu :
Eni Sumarminingsih SSi, MM.
Kelompok :
1. Danny Prasetyo Hartanto (0810950034)
2. Mahardika Dwi Jayanti (0810950050)
3. Sabrina Yunitasari (0810950064)
4. Efrida Dwi Candrawati(0810953034)
5. Meirizal Dwi Ebtiyanto (0810953046)
PRODI STATISTIKA
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN
ALAM
UNIVERSITAS BRAWIJAYA
MALANG
2011
BAB I
PENDAHULUAN
1.1 Latar Belakang

Sebagaimana dalam regresi linier, model umum dari regresi logistik
ganda adalah model regresi ganda yaitu model yang melibatkan lebih dari satu
prediktor/variable independen. Secara garis besar, langkah pemodelan regresi
logistik tidaklah berbeda dengan kasus regresi liner.
Regresi logistic adalah model yang paling penting untuk respon data
kategori. Regresi logistic digunakan semakin dalam berbagai aplikasi. Mulanya
regresi logistic digunakan dalam studi biomedis, tetapi 20 tahun terakhir juga
telah banyak digunakan dalam penelitian ilmu sosial dan pemasaran.
Baru-baru ini, regresi logistik telah menjadi alat populer di aplikasi bisnis.
Beberapa aplikasi kredit - scoring menggunakan regresi logistik untuk model
probabilitas dengan subjek adalah kredit layak. Sebagai contoh, probabilitas
bahwa suatu subjek membayar tagihan tepat waktu dapat menggunakan
prediktor seperti ukuran tagihan, pendapatan tahunan, pekerjaan, hipotek dan
kewajiban hutang, persentase tagihan dibayar tepat waktu di masa lalu, dan
aspek lain dari pemohon kredit sebuah sejarah. Sebuah perusahaan yang
bergantung pada penjualan katalog dapat menentukan apakah kirim katalog ke
pelanggan potensial dengan pemodelan probabilitas penjualan sebagai fungsi
dari indeks perilaku pembelian masa lalu.
1.2 Tujuan
Mempelajari regresi logistic secara mendalam dan memecahkan berbagai
permasalahan menggunakan regresi logistic.
1.3 Kasus
Sebuah dealer mobil ingin mengetahui kondisi konsumen yang menjadi
target pasarnya, maka dilakukan studi mengenai keputusan seseorang untuk
membeli mobil atau tidak. Berdasarkan survey yang dilakukan, keputusan
membeli mobil atau tidak dipengaruhi oleh beberapa variabel yaitu jumlah
pendapatan, status pernikahan, lokasi tempat tinggal, jumlah keluarga, dan
tingkat pendidikan.
Tujuan dari penelitian ini adalah untuk mengetahui:1. Apakah status pernikahan dan pendapatan mempengaruhi keputusan
seseorang membeli mobil2. Jika ditambah variabel lagi (lokasi tempat tinggal, jumlah keluarga,
tingkat pendidikan) apakah variabel baru tersebut juga mempengruhi keputusan membeli mobil
Berikut data hasil kuisioner mengenai keputusan membeli mobil 30 rumah
tangga :
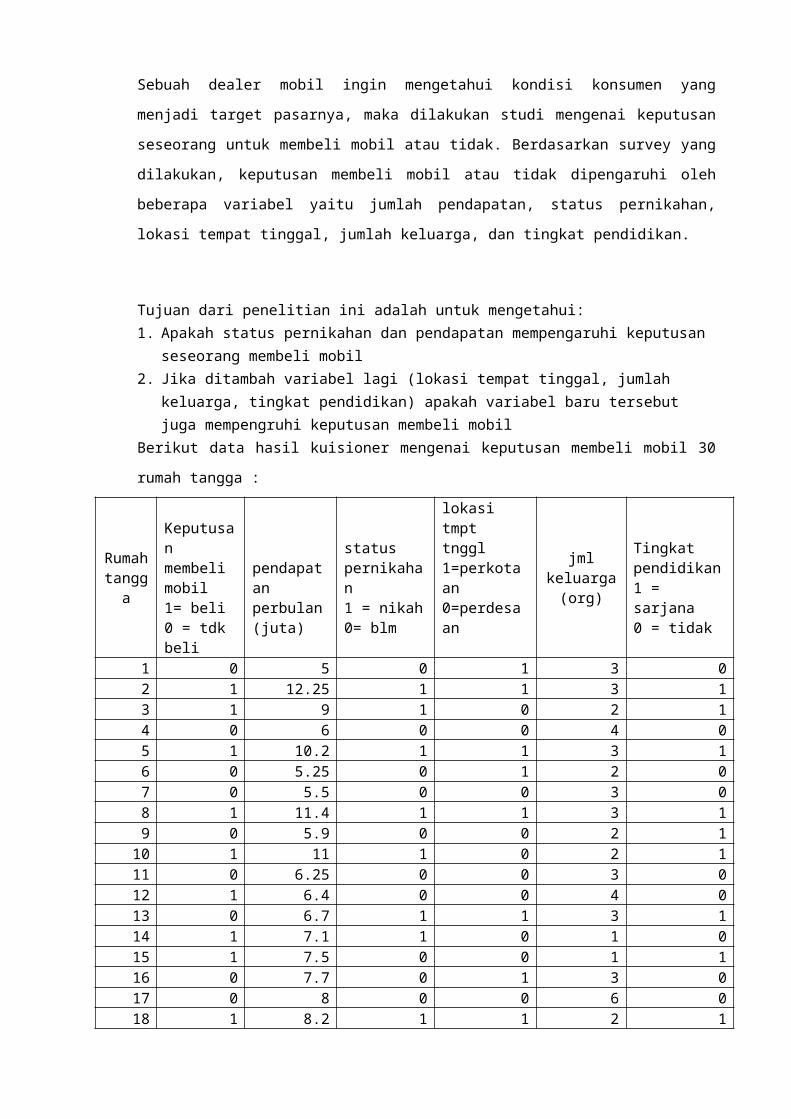
Rumah
tangga
Keputusan membeli mobil1= beli0 = tdk beli
pendapatan perbulan (juta)
status pernikahan1 = nikah0= blm
lokasi tmpt tnggl1=perkotaan0=perdesaan
jml keluarga
(org)
Tingkat pendidikan1 = sarjana0 = tidak
1 0 5 0 1 3 02 1 12.25 1 1 3 13 1 9 1 0 2 14 0 6 0 0 4 05 1 10.2 1 1 3 16 0 5.25 0 1 2 07 0 5.5 0 0 3 08 1 11.4 1 1 3 19 0 5.9 0 0 2 1
10 1 11 1 0 2 111 0 6.25 0 0 3 012 1 6.4 0 0 4 013 0 6.7 1 1 3 114 1 7.1 1 0 1 015 1 7.5 0 0 1 116 0 7.7 0 1 3 017 0 8 0 0 6 018 1 8.2 1 1 2 119 0 8.5 0 0 2 020 1 8.6 1 1 3 121 0 8.8 0 1 5 022 0 5.8 1 0 2 023 1 9.4 1 1 3 124 1 9.75 1 1 2 125 1 9.9 1 1 3 126 1 10.6 1 1 2 127 1 10.8 1 1 3 128 0 6.95 0 1 2 029 1 11.8 1 1 2 130 1 12 1 1 3 1
BAB II
ANALISIS STATISTIKA
2.1 Tinjauan Teori
Tujuan dari model regresi dengan respon kualitatif pada variabel
dependen adalah untuk menentukan probabilitas individu dalam keputusan yang
bersifat kualitatif.
Model cumulatif distribution function (CDF) adalah sebuah model yang
mampu menjamin bahwa nilainya terletak antara 0 dan 1 sehingga dapat
membuat model regresi dimana respon dari variabel dependen bersifat
dikotomis yakni 0 dan 1 terpenuhi.
Ada dua model yang memenuhi kriteria dari cdf yaitu model logit dan
model probit. Model logit berkaitan dengan fungsi probabilitas distribusi
logistik. Sedangkan model probit berkaitan dengan fungsi probabilitas distribusi
normal.
Metode Estimasi Maximum Likelihood
Didalam regresi dengan menggunakan metode maksimum likelihood,
tidak mencari koefisien regresi yang mampu meminimumkan jumlah residual
kuadrat sebagaimana metode OLS dalam regresi linear berganda. Metode
maximum likelihood adalah mencari koefisien regresi sehingga probabilitas
kejadian dari variable dependen bisa setinggi mungkin atau bisa semaksimum
mungkin. Besarnya probabilitas yang memaksimumkan kejadian ini disebut log
of the likelihood (LL). Dengan demikian nilai LL ini merupakan ukuran kebaikan
garis regresi logistic di dalam metode maximum likelihood sebagaimana jumlah
residual kuadrat di dalam regresi linear.
Ada dua cara mengestimasi model regresi logistic yaitu metode secara
menyeluruh dan secara bertahap.
1. Secara menyeluruh. Kita memasukkan semua variable independen
kemudian baru dievaluasi variable independen mana yang berpengaruh
(signifikan) terhadap variable dependen.
2. Secara bertahap (stepwise). Metode ini dilakukan dengan memilih secara
otomatis hanya kepada variable-variabel independen yang berpengaruh
terhadap variable dependen.
Evaluasi Hasil

Sebagai bagian dari metode statistika multivariat, hasil regresi logistik
sebagai salah satu bentuk analisis regresi memerlukan sebuah evaluasi untuk
mengetahui seberapa baik hasil regresi logistik kita. Evaluasi hasil regresi
logistik meliputi :
1. Penilaian seberapa baik (goodness of fit) model regresi
Goodness of fit dalam regresi logistik adalah untuk mengetahui kebaikan
model sebagaimana uji goodness of fit model regresi linear berganda
dengan menggunakan ukuran koefisien determinasi
2. Uji signifikansi pengaruh semua variabel independen secara serentak
terhadap variabel dependen (overall model fit)
Uji statistika untuk mengetahui apakah semua variabel independen di
dalam regresi logistik secara serentak mempengaruhi variabel dependen
sebagaimana uji F dalam regresi linear didasarkan pada nilai statistika -
2LL atau nilai LR
3. Uji signifikansi pengaruh variabel independen terhadap variabel
dependen secara individual (significance test)
Setelah kita menguji kebaikan garis regresi dan uji serempak, maka
selanjutnya adalah melakukan uji signifikansi variabel independen secara
individual. Uji signifikansi variabel independen ini sama dengan uji
signifikansi menggunakan uji t pada model regresi linear berganda.
Uji signifikansi pada model logit dilakukan sama dengan uji t pada regresi
linear berganda, yaitu untuk mengetahui apakah koefisien variabel
independen di dalam model logit berbeda 0 atau tidak. Uji signifikansi
model logit ini menggunakan uji statistika Wald. Dari uji Wald ini kita bisa
mengetahui apakah variabel independen mempengaruhi variabel
dependen di dalam model regresi logistik.
2.2 Metodologi
Dalam melakukan analisis regresi logistic ini, digunakan bantuan minitab
14 dan SPSS 15. Langkah – langkahnya adalah sebagai berikut:
Langkah pertama adalah melakukan analisis regresi logistic sebagai
berikut
1. Klick Stat > binary logistic regression

2. Masukkan variabel Y kedalam kolom response, variable X1(pendapatan),
X2 (status pernikahan), X3 (tempat tinggal), X4 (jumlah keluarga), dan X5
(tingkat pendidikan) kedalam kolom model, klik options : pilih Link
function yang akan digunakan (Logit, Nomit/ Probit, Gompit)
3. Klick OK
BAB III
PEMBAHASAN
3.1 Hasil Analisis
Analisis Regresi Logistik untuk Faktor Pendapatan dan Status
Pernikahan
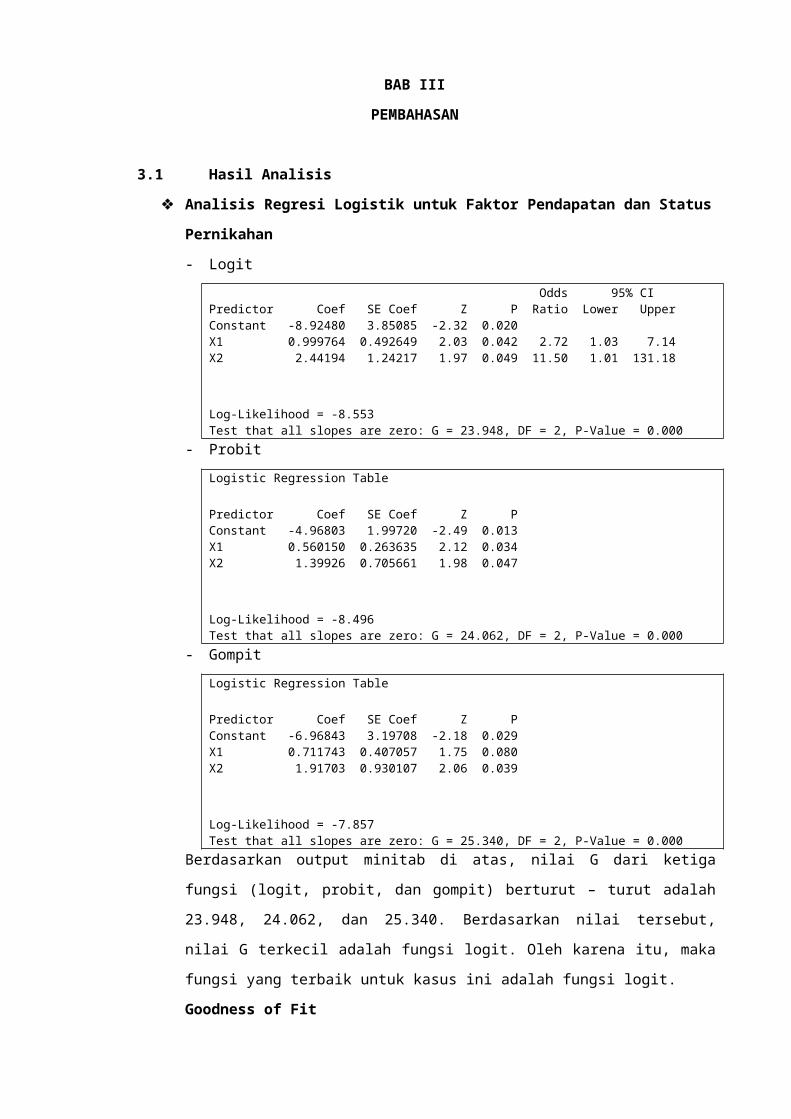
- Logit
Odds 95% CIPredictor Coef SE Coef Z P Ratio Lower UpperConstant -8.92480 3.85085 -2.32 0.020X1 0.999764 0.492649 2.03 0.042 2.72 1.03 7.14X2 2.44194 1.24217 1.97 0.049 11.50 1.01 131.18
Log-Likelihood = -8.553Test that all slopes are zero: G = 23.948, DF = 2, P-Value = 0.000
- Probit
Logistic Regression Table
Predictor Coef SE Coef Z PConstant -4.96803 1.99720 -2.49 0.013X1 0.560150 0.263635 2.12 0.034X2 1.39926 0.705661 1.98 0.047
Log-Likelihood = -8.496Test that all slopes are zero: G = 24.062, DF = 2, P-Value = 0.000
- Gompit
Logistic Regression Table
Predictor Coef SE Coef Z PConstant -6.96843 3.19708 -2.18 0.029X1 0.711743 0.407057 1.75 0.080X2 1.91703 0.930107 2.06 0.039
Log-Likelihood = -7.857Test that all slopes are zero: G = 25.340, DF = 2, P-Value = 0.000
Berdasarkan output minitab di atas, nilai G dari ketiga fungsi (logit,
probit, dan gompit) berturut – turut adalah 23.948, 24.062, dan
25.340. Berdasarkan nilai tersebut, nilai G terkecil adalah fungsi logit.
Oleh karena itu, maka fungsi yang terbaik untuk kasus ini adalah
fungsi logit.
Goodness of Fit
Goodness-of-Fit Tests
Method Chi-Square DF PPearson 22,1578 27 0,729Deviance 17,1059 27 0,928Hosmer-Lemeshow 12,8238 8 0,118
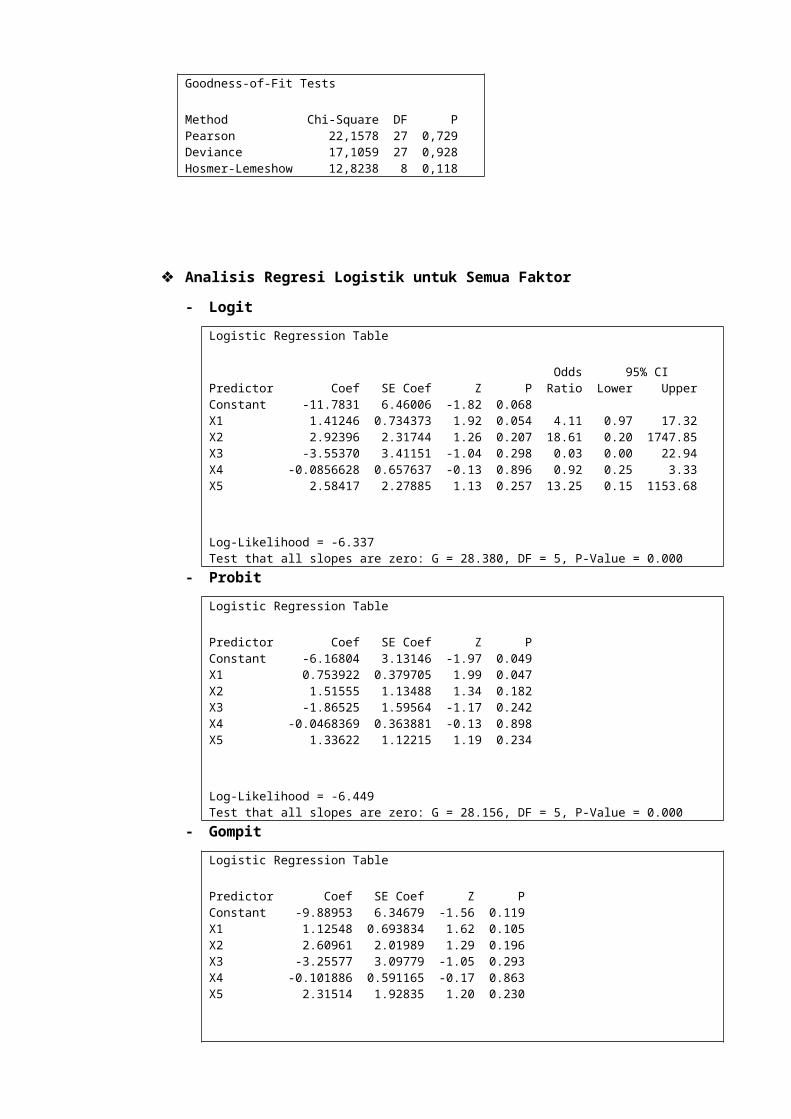
Analisis Regresi Logistik untuk Semua Faktor
- Logit
Logistic Regression Table
Odds 95% CIPredictor Coef SE Coef Z P Ratio Lower UpperConstant -11.7831 6.46006 -1.82 0.068X1 1.41246 0.734373 1.92 0.054 4.11 0.97 17.32X2 2.92396 2.31744 1.26 0.207 18.61 0.20 1747.85X3 -3.55370 3.41151 -1.04 0.298 0.03 0.00 22.94X4 -0.0856628 0.657637 -0.13 0.896 0.92 0.25 3.33X5 2.58417 2.27885 1.13 0.257 13.25 0.15 1153.68
Log-Likelihood = -6.337Test that all slopes are zero: G = 28.380, DF = 5, P-Value = 0.000
- Probit
Logistic Regression Table
Predictor Coef SE Coef Z PConstant -6.16804 3.13146 -1.97 0.049X1 0.753922 0.379705 1.99 0.047X2 1.51555 1.13488 1.34 0.182X3 -1.86525 1.59564 -1.17 0.242X4 -0.0468369 0.363881 -0.13 0.898X5 1.33622 1.12215 1.19 0.234
Log-Likelihood = -6.449Test that all slopes are zero: G = 28.156, DF = 5, P-Value = 0.000
- Gompit
Logistic Regression Table
Predictor Coef SE Coef Z PConstant -9.88953 6.34679 -1.56 0.119X1 1.12548 0.693834 1.62 0.105X2 2.60961 2.01989 1.29 0.196X3 -3.25577 3.09779 -1.05 0.293X4 -0.101886 0.591165 -0.17 0.863X5 2.31514 1.92835 1.20 0.230
Log-Likelihood = -5.589Test that all slopes are zero: G = 29.876, DF = 5, P-Value = 0.000
Berdasarkan output minitab di atas, nilai G dari ketiga fungsi (logit,
probit, dan gompit) berturut – turut adalah 28.380, 28.156, dan
29.876. Berdasarkan nilai tersebut, nilai G terkecil adalah fungsi
probit. Oleh karena itu, maka fungsi yang terbaik untuk kasus ini
adalah fungsi probit.
Goodness of Fit
Goodness-of-Fit Tests
Method Chi-Square DF PPearson 19.5688 24 0.721Deviance 12.8982 24 0.968Hosmer-Lemeshow 7.2789 8 0.507
3.2 Interpretasi
Analisis Regresi Analisis Regresi Logistik untuk Seluruh Faktor
Berdasarkan output minitab di atas, didapatkan persamaan regresi
logistik untuk data pada kasus tersebut adalah sebagai berikut:
μ ( x )=P(Y=1)= e−8.92480+0.999764 X1+2.44194 X 2
1+e−8.92480+0.999764 X 1+2.44194 X 2
sehingga
log(p/(1-p)) = -8.92480 + 0.999764 status pernikahan + 2.44194
pendapatan per bulan
P-value yang didapatkan dari output semuanya bernilai kurang dari
α(0.05), sehingga dapat disimpulkan bahwa kedua faktor (pendapatan
dan status perkawinan) secara simultan berpengaruh signifikan
terhadap keputusan seseorang membeli mobil.
Goodness of Fit
Kebaikan model dapat dilihat dari nilai Chi-square dan atau p-value
dari output yang tersebut di atas. Berdasarkan output, didapatkan p-
value dari metode Pearson sebesar 0.729. Nilai tersebut lebih besar
dari α(0.05), sehingga model tersebut cukup layak untuk mengepaskan
data. Begitu juga dengan p-value dari metode deviance dan Hosmer-
Lameshow juga lebih besar dari α(0.05). sehingga model tersebut
cukup layak untuk mengepaskan data.
Odds Ratio
Implikasi hasil analisis logistik pada setiap faktor berbeda-
berbeda sesuai dengan nilai odds ratio yang didapat dari model.
Oods ratio yang muncul dari analisis logistik menggambarkan
rasio peluang kejadian sukses dari setiap peubah respon.
Berdasarkan output minitab, didapatkan nilai odds untuk
variabel X1 sebesar 2.72, hal ini menunjukkan bahwa seseorang
berpeluang 2.72 kali untuk membeli mobil dibandingkan tidak
membeli mobil akibat pengaruh peningkatan pendapatannya.
Begitu juga dengan nilai odds ratio untuk variabel X2 sebesar
11.50, hal ini menunjukkan bahwa seseorang berpeluang 11.50
kali untuk membeli mobil dibandingkan tidak membeli mobil
akibat telah menikah.
Analisis Regresi Analisis Regresi Logistik untuk Seluruh Faktor
Berdasarkan output minitab di atas, didapatkan persamaan regresi
logistik untuk data pada kasus tersebut adalah sebagai berikut:
μ ( x )=P (Y=1 )= e−11.7831+1.41246 X 1+2.9231X 2−3.55370 X 3−0.0856628 X 4+2.58417 X 5
1+e−11.7831+1.41246 X 1+2.9231 X2−3.55370 X 3−0.0856628X 4+2.58417 X5
Sehingga,
log(p/(1-p)) = -11.7831 + 1.41246 pendapatan per bulan + 2.92396
status pernikahan – 3.55370 tempat tinggal – 0.0856628 jumlah
keluarga + 2.58417 tingkat pendidikan
P-value yang didapatkan dari output ada yang bernilai kurang dari
α(0.05) dan ada yang lebih dari α(0.05), sehingga dapat disimpulkan
bahwa faktor pendapatan berpengaruh signifikan terhadap keputusan
seseorang membeli mobil, sedangkan faktor lainnya tidak berpengaruh
secara signifikan terhadap keputusan seseorang membeli mobil.
Goodness of Fit
Kebaikan model dapat dilihat dari nilai Chi-square dan atau p-value
dari output yang tersebut di atas. Berdasarkan output, didapatkan p-
value dari metode Pearson sebesar 0.721. Nilai tersebut lebih besar
dari α(0.05), sehingga model tersebut cukup layak untuk mengepaskan
data. Begitu juga dengan p-value dari metode deviance dan Hosmer-
Lameshow juga lebih besar dari α(0.05). sehingga model tersebut
cukup layak untuk mengepaskan data.
Odds Ratio
Dengan bantuan minitab, odds ratio hanya bisa didapatkan
dengan metode logit. Berdasarkan output minitab, didapatkan
nilai odds untuk variabel X1 sebesar 4.11, hal ini menunjukkan
bahwa seseorang berpeluang 4.11 kali untuk membeli mobil
dibandingkan tidak membeli mobil akibat pengaruh peningkatan
pendapatannya. Begitu juga dengan nilai odds ratio untuk
variabel X2 sebesar 18.61, hal ini menunjukkan bahwa
seseorang berpeluang 18.61 kali untuk membeli mobil
dibandingkan tidak membeli mobil akibat telah menikah. Begitu
seterusnya.

BAB IV
PENUTUP
3.1 Kesimpulan
Berdasarkan uraian diatas dapat disimpulkan bahwa:
1. Analisis regresi logistik digunakan jika peneliti ingin mengetahui
pengaruh antar variabel dependen dengan variabel independen, jika
variabel dependennya berupa kategori.
2. Ada beberapa model dalam analisis regresi logistic, yaitu logit, probit,
dan gompit.
3. Metode estimasi yang digunakan dalam analisis regresi adalah metode
maksimum likelihood. Dalam analisis regresi logistic, metode ini
bertujuan untuk mendapatkan koefisien yang menghasilkan probabilitas
kejadian dari variabel dependen yang maksimal.
4. Dalam kasus di atas, dapat diketahui bahwa variabel jumlah pendapatan
dan status pernikahan secara simultan berpengaruh signifikan terhadap
keputusan seseorang dalam membeli mobil. Akan tetapi setelah
ditambahkan variabel yang lain (lokasi tempat tinggal, jumlah keluarga,
dan tingkat pendidikan), variabel status pernikahan dan variabel
tambahan tersebut, menjadi tidak berpengaruh signifikan secara simultan
terhadap keputusan seseorang dalam membeli mobil.

DAFTAR PUSTAKA
J.B. Ramsey.1969.TEST FOR SPESIFICATION ERRORS IN CLASSICAL LINIEAR
LEAST SQUARE REGRESSION ANALYSIS.Journal of the Royal Statistical
Society, Series B
Kleinbaum,David G, Lawrence L. Kupper, Azhar Nizam, and Keith E.
Muller.2008.APPLIED REGRESSION ANALYSIS AND OTHER
MULTIVARIATE METHOD. California : Thompson
Widarjono,Agus.2010.ANALISIS STATISTIKA MULTIVARIAT
TERAPAN.Yogyakarta:UPP STIM YKPN


















