Kaidah Sebaran Dalam Statistika
38
1 KAIDAH-KAIDAH SEBARAN DALAM STATISTIKA 1. Distribusi teoritis 1.1 Distribusi Dasar terpenting untuk memahami distribusi utamanya distirbusi data di dalam statistika adalah pengetahuan tentang probabilitas ( probability), tapi mengingat dasar probabilitas ini memerlukan uraian yang cukup panjang meskipun topik ini yang kita angkat, tentunya kita persilahkan dosen saja yang menjelaskan lebih detail meskipun hanya dasar-dasar saja (karena kita tidak sedang berada dalam jurusan statistik). Bagi yang ingin mempelajari dari dasar tentang teori distribusi probabilitas, silahkan mencari referensi dari buku statistik yang ada. 1.1.1 Jenis dan Bentuk Distribusi Telah kita ketahui bahwa data bisa dikelompokkan dalam atribute data dan variable/continuous data. Oleh karena itu, distribusi data secara umum juga bisa dibagi dua yakni discrete distributions (untuk non-continous data) dan continuous distribution. selain itu, bentuk distribusi cukup penting dalam menganalisis data; dimana secara umum bentukdistribusi bisa dibagi menjadi: - Simetris, bila rata-rata = median, atau angka skewness = 0 - Right –Skewed (Positif), bila rata-rata > median - Left-Skewed (Negatif), bila rata-rata <median
-
Upload
risky-yudha -
Category
Documents
-
view
619 -
download
19
Transcript of Kaidah Sebaran Dalam Statistika

1
KAIDAH-KAIDAH SEBARAN DALAM STATISTIKA
1. Distribusi teoritis
1.1 Distribusi
Dasar terpenting untuk memahami distribusi utamanya distirbusi data di dalam statistika
adalah pengetahuan tentang probabilitas (probability), tapi mengingat dasar probabilitas ini
memerlukan uraian yang cukup panjang meskipun topik ini yang kita angkat, tentunya kita
persilahkan dosen saja yang menjelaskan lebih detail meskipun hanya dasar-dasar saja (karena
kita tidak sedang berada dalam jurusan statistik). Bagi yang ingin mempelajari dari dasar tentang
teori distribusi probabilitas, silahkan mencari referensi dari buku statistik yang ada.
1.1.1 Jenis dan Bentuk Distribusi
Telah kita ketahui bahwa data bisa dikelompokkan dalam atribute data dan
variable/continuous data. Oleh karena itu, distribusi data secara umum juga bisa dibagi dua
yakni discrete distributions (untuk non-continous data) dan continuous distribution. selain itu,
bentuk distribusi cukup penting dalam menganalisis data; dimana secara umum bentukdistribusi
bisa dibagi menjadi:
- Simetris, bila rata-rata = median, atau angka skewness = 0
- Right –Skewed (Positif), bila rata-rata > median
- Left-Skewed (Negatif), bila rata-rata <median

2
1.2 Peubah Acak
Fungsi yang mendefinisikan titik-titik contoh dalam ruang contoh sehingga memiliki nilai
berupa bilangan nyata disebut : PEUBAH ACAK = VARIABEL ACAK = RANDOM
VARIABLE (beberapa buku juga menyebutnya sebagai STOCHASTIC VARIABLE )
X dan x
Biasanya PEUBAH ACAK dinotasikan sebagai X (huruf besar : X ) Nilai dalam X
dinyatakan sebagai x (huruf kecil : x).
Contoh 1 :
Pelemparan sekeping Mata Uang setimbang sebanyak 3 Kali Berarti ruang contoh sebanyak 23
atau
S : {GGG, GGA, GAG, AGG, GAA, AGA, AAG, AAA}
dimana G = GAMBAR dan A = ANGKA
X: setiap satu sisi GAMBAR bernilai satu (G = 1)
S : {GGG, GGA, GAG, AGG, GAA, AGA, AAG, AAA
3 2 2 2 1 1 1 0
(0 = tidak mengandung G)
Perhatikan bahwa X{0,1,2,3}
Nilai x1= 0, x2= 1 x3= 2, x4= 3

3
1.2.1 Kategori Peubah Acak
Peubah Acak dapat dikategorikan menjadi:
a. Peubah Acak Diskrit : nilainya berupa bilangan cacah, dapat dihitung dan terhingga.
R untuk hal-hal yang dapat dicacah
Misal : - Banyaknya Produk yang rusak = 12 buah
- Banyak pegawai yang di-PHK = 5 orang
b. Peubah Acak Kontinyu : nilainya berupa selang bilangan, tidak dapat di hitung dan tidak
terhingga (memungkinkan pernyataan dalam bilangan pecahan)
R untuk hal-hal yang diukur (jarak, waktu, berat, volume)
Misal : - Jarak Pabrik ke Pasar = 35.57 km
- Waktu produksi per unit = 15.07 menit
- Berat bersih produk = 209.69 gram
1.2.2 Distribusi Peluang Teoritis
Distribusi Peluang Teoritis : Tabel atau Rumus yang mencantumkan semua kemungkinan
nilai peubah acak berikut peluangnya.
Karena berhubungan dengan kategori peubah acak, maka dikenal :
a. Distribusi Peluang Diskrit : Seragam*), Binomial*), Hipergeometrik*), Poisson*)
b. Distribusi Peluang Kontinyu : Normal*) t, F, χ² (chi kuadrat)
*) Hal-hal yang berkaitan dengan tema makalah sehingga ; termasuk bahan yang akan di bahas

4
2. Distribusi Peluang Diskrit
Didalam Distribusi discrete terdapat empat distribusi yang paling sering
digunakan yakni distribusi peluang seragam, binomial distribution, Poisson distribution
dan distribusi hipergeometrik.
2.1 Distribusi Peluang Seragam
Definisi Distribusi Peluang Seragam :
Jika Peubah Acak X mempunyai nilai x1, x2, x3,...,xk yang berpeluang sama, maka distribusi
peluang seragamnya adalah :
f(x;k) =
untuk x = x1, x2, x3,...,xk
Contoh 2 :
Jika Abi, Badu dan Cici berpeluang sama mendapat beasiswa, maka distribusi peluang
seragamnya adalah :
f(x; 3) =
untuk x = Abi, Badu, Cici atau x =1,2,3(mahasiswa dinomori)
Secara umum : nilai k dapat dianggap sebagai kombinansi N dan n
k =
N = banyaknya titik contoh dalam ruang contoh/populasi
n = ukuran sampel acak = banyaknya unsur peubah acak X
Contoh 3 :
Jika kemasan Batu Baterai terdiri dari 4 batu baterai, maka bagaimana distribusi peluang
seragam cara menyusun batu baterai untuk 12 batu baterai?
k = =
=
= 495 R ada 495 cara
f(x; k) = f(x; 495) = untuk x = 1,2,3,...,495

5
2.2 Distribusi Binomial (binomial distribution)
Distribusi binomial adalah suatu distribusi probabilitas yang dapat digunakan bilamana
suatu proses sampling dapat diasumsikan sesuai dengan proses Bernoulli. Penemu Distribusi
Binomial adalah James Bernaulli sehingga dikenal sebagai Distribusi Bernaulli. Menggambarkan
fenomena dengan dua hasil atau outcome.
Misalkan anda seorang penggemar permainan basket dan sedang ingin melatih
kemampuan memasukkan bola ke keranjang dari titik lemparan bebas (free throw). Anda
melakukan tembakan sepuluh kali tiap set; dari beberapa set tembakan ternyata rata-rata
tembakan anda adalah anda hanya memasukkan 5 bola dari 10 lemparan, dalam hal ini anda
mempunyai nilai kemungkinan bola masuk = 0.5. Dari data ini kita bisa menghitung berapa
kemungkinan kita memasukkan bola jika kita melempar sebanyak 200 kali. Ini adalah contoh
sederhana dari aplikasi distribusi binomial.
Setiap variabel yang bisa diukur dengan probability seperti diatas dimana suatu kejadian
hanya bisa dimasukkan dalam dua kategori (berhasil/gagal, masuk/keluar, bagus/cacat,dll) bisa
dikategorikan dalam distribusi binomial.
Rata-rata dari distribusi binomial adalah:
μ = np
dimana, μ = rata-rata
n = besarnya sample
p = probability of success (probability of “something”)
Standar deviasi:
Percobaan Binomial biasanya juga yang mempunyai ciri-ciri sebagai berikut:
1. Percobaan diulang n kali
2. Hasil setiap ulangan hanya dapat dikategorikan ke dalam 2 kelas;
Misal: "BERHASIL" atau "GAGAL"
("YA" atau "TIDAK"; "SUCCESS" or "FAILED")
3. Peluang keberhasilan = p dan dalam setiap ulangan nilai p tidak berubah.

6
Peluang gagal = q = 1- p.
4.Setiap ulangan bersifat bebas satu dengan yang lain.
Peluang berhasil atau sukses dinyatakan dengan p dan dalam setiap ulangan nilai p dan
setiap nilai p bersifat tetap. Sedangkan peluang yang gagal dinyatakan dengan q, dimana q=1-p
Setiap percobaan bersifat bebas atau independen satu dengan yang lainnya. Percobaan
terdiri atas n ulangan.
Percobaan terdiri atas n usaha yang saling independen
Tiap usaha hanya terdiri dari dua kejadian yang mungkin, sukses atau gagal.
Probabilitas sukses pada tiap percobaan haruslah sama dan dinyatakan dengan p.
Jumlah percobaan yang merupakan komponen eksperimen binomial harus tertentu.
Sehingga dapat disimpulkan
Definisi Distribusi Peluang Binomial
b(x;n,p) = untuk x = 0,1,23,...,n
n: banyaknya ulangan
x: banyak keberhasilan dalam peubah acak X
p: peluang berhasil pada setiap ulangan
q: peluang gagal = 1 - p pada setiap ulangan
Catatan : untuk memudahkan membedakan p dengan q, anda terlebih dahulu harus dapat
menetapkan mana kejadian SUKSES mana yang GAGAL. Anda dapat
menetapkan bahwa kejadian yang ditanyakan adalah = kejadian SUKSES
fungsi probabilitas binomial
)()1()!(!
!)( xnx pp
xnx
nxf

7
x =banyaknya sukses yang terjadi dalam n kali ulangan
p =probabilita “sukses”
n =banyaknya ulangan
2.3 Distribusi Peluang Poisson
Distribusi poisson ditemukan oleh S.D. Poisson (1781-1841) seorang ahli matematika
berkebangsaan Perancis dimana distribusi poisson adalh salah satu jenis distribusi teoritis diskrit.
Definisi distribusi poisson menurut Walpole(1995) distribusi poison merupakan distribusi
peluang acak poisson x, yang menyatakan banyaknya sukses yang terjadi selama selang waktu
tertentu. Menurut beberapa literatur distribusi poisson merupakan Distribusi nilai-nilai bagi suatu
variabel random X (X diskret), yaitu banyaknya hasil percobaan yang terjadi dalam suatu
interval waktu tertentu atau di suatu daerah tertentu.
Definisi yang lain menyatakan Distribusi probabilitas diskret yang menyatakan peluang
jumlah peristiwa yang terjadi pada periode waktu tertentu apabila rata-rata kejadian tersebut
diketahui dan dalam waktu yang saling bebas sejak kejadian terakhir.
Distribusi poison memiliki beberapa cirri:
Banyaknya hasil percobaan yang terjadi dalam suatu interval waktu atau suatu
daerah tertentu tidak bergantung pada banyaknya hasil percobaan yang terjadi pada
interval waktu atau daerah lain yang terpisah.
Probabilitas terjadinya hasil percobaan selama suatu interval waktu yang singkat
atau dalam suatu daerah yang kecil, sebanding dengan panjang interval waktu atau
besarnya daerah tersebut dan tidak bergantung pada banyaknya hasil percobaan yang
terjadi di luar interval waktu atau daerah tersebut.
Probabilitas lebih dari satu hasil percobaan yang terjadi dalam interval waktu yang
singkat atau dalam daerah yang kecil dapat diabaikan.

8
Distribusi poisson sering digunakan untuk:
1. Menghitung probabilitas terjadinya peristiwa menurut satuan waktu, ruang atau isi,
luas, panjang tertentu, seperti menghitung probabilitas dari:
1. Banyaknya penggunaan telepon per menit atau banyaknya mobil yang lewat selama
5 menit di suatu ruas jalan,
2. Banyaknya bakteri dalam satu tetes atau 1 liter air,
3. Banyaknya kesalahan ketik per halaman sebuah buku, dan
4. Banyaknya kecelakaan mobil di jalan tol selama minggu pertama bulan Oktober.
5. Menghitung distribusi binomial apabila nilai n besar (n ≥ 30) dan p kecil (p<0,1).
Definisi Distribusi Peluang Poisson :
Perhatikan rumus yang digunakan! Peluang suatu kejadian Poisson hitung dari rata-rata populasi
poisson x
poisson(x:µ)= /x!
e : bilangan natural = 2.71828...
x : banyaknya unsur BERHASIL dalam sampel
ƒÊ : rata-rata keberhasilan

9
Tabel Peluang Poisson
Seperti halnya peluang binomial, soal-soal peluang Poisson dapat diselesaikan dengan Tabel
Poisson
Cara membaca dan menggunakan Tabel ini tidak jauh berbeda dengan Tabel Binomial
Misal: x µ= 4,5 µ= 5,0
0 0.0111 0.0067
1 0.0500 0.0337
2 0.1125 0.0842
3 0.1687 0.1404
dst dst dst
15 0.0001 0.0002
poisson(2; 4.5) = 0.1125
poisson(x < 3; 4.5) = poisson(0;4.5) + poisson(1; 4.5)+ poisson(2; 4.5)
= 0.0111 + 0.0500 + 0.1125 = 0.1736
poisson(x > 2;4.5) = poisson(3; 4.5) + poisson(4; 4.5) +...+ poisson(15;4.5)
atau
= 1 - poisson(x •’ 2)
= 1 - [poisson(0;4.5) + poisson(1; 4.5)+ poisson(2; 4.5)]
= 1 - [0.0111 + 0.0500 + 0.1125 ] = 1 - 0.1736 = 0.8264
Contoh 4:
Rata-rata seorang sekretaris baru melakukan 5 kesalahan ketik per halaman. Berapa peluang
bahwa pada halaman berikut ia membuat:
a. tidak ada kesalahan?(x = 0)
b. tidak lebih dari 3 kesalahan?( x •’ 3)
c. lebih dari 3 kesalahan?(x >3)
d. paling tidak ada 3 kesalahan (x 3 3)

10
Jawab:
ƒÊ = 5
a. x = 0 R dengan rumus? hitung poisson(0; 5)
atau
R dengan Tabel Distribusi Poisson
di bawah x:0 dengan ƒÊ = 5.0 R (0; 5.0) = 0.0067
b. x •’ 3 R dengan Tabel Distribusi Poisson hitung
poisson(0; 5.0) + poisson(1; 5.0) + poisson(2; 5.0) + poisson(3; 5.0) = 0.0067 + 0.0337 + 0.0842
+ 0.1404 = 0.2650
c. x > 3 R poisson( x > 3; 5.0) = poisson(4; 5.0) + poisson(5; 5.0) + poisson (6; 5.0) + poisson(7;
5.0) + ... + poisson(15; 5.0)
atau
R poisson(x >3) = 1 - poisson(x•’3)
= 1 - [poisson(0; 5.0) + poisson(1; 5.0) + poisson(2; 5.0) +poisson(3; 5.0)]
= 1 - [0.0067 + 0.0337 + 0.0842 + 0.1404]
= 1 - 0.2650
= 0.7350
Pendekatan Poisson untuk Distribusi Binomial :
. Pendekatan Peluang Poisson untuk Peluang Binomial, dilakukan jika n besar (n > 20) dan p
sangat kecil (p < 0.01) dengan terlebih dahulu menetapkan p dan kemudian menetapkan ƒÊ
= n x p
Contoh 5 :
Dari 1000 orang mahasiswa 2 orang mengaku selalu terlambat masuk kuliah setiap hari, jika
pada suatu hari terdapat 5 000 mahasiswa, berapa peluang ada lebih dari 3 orang yang terlambat?
Kejadian Sukses : selalu terlambat masuk kuliah
p =2/1000 = 0.002 n = 5 000 x > 3

11
jika diselesaikan dengan peluang Binomial R b(x > 3; 5 000, 0.002)
tidak ada di Tabel, jika menggunakan rumus sangat tidak praktis.
p = 0.002 n = 5 000 x>3
ƒÊ = n •~ p = 0.002 •~ 5 000 = 10
diselesaikan dengan peluang Poisson R poisson (x > 3; 10) = 1 - poisson (x •’ 3)
= 1 - [poisson (0;10) + poisson(1; 10) + poisson(2;10) + poisson(3; 10)
= 1 - [0.0000 + 0.0005 + 0.0023 ] = 1 - 0.0028 = 0.9972
2.4 Distribusi Peluang Hipergeometrik
Perbedaan Peluang Binomial hanya untuk peluang BERHASIL dengan Peluang
Hipergeometrik untuk kasus di mana peluang BERHASIL berkaitan dengan Peluang GAGAL,
ada penyekatan dan pemilihan/kombinasi obyek (BERHASIL dan GAGAL)
Percobaan hipergeometrik Mempunyai ciri-ciri sebagai berikut:
1. Contoh acak berukuran n diambil dari populasi berukuran N
2. k dari N diklasifikasikan sebagai "BERHASIL" sedangkan N-k diklasifikasikan sebagai
"GAGAL"
Rata-rata dan ragam bagi distribusi Hipergeometrik h(x;N,n,k) adalah
Rata-rata=µ=nk/N ragam= /N-1).n.(k/N-(1-k/N))

12
Definisi Distribusi Hipergeometrik:
Bila dalam populasi N obyek, k benda termasuk kelas "BERHASIL" dan N-k (sisanya) termasuk
kelas "GAGAL", maka Distribusi Hipergeometrik peubah Acak X yg menyatakan banyaknya
keberhasilan dalam contoh acak berukuran n adalah :
Contoh 6 :
Jika dari seperangkat kartu bridge diambil 5 kartu secara acak tanpa pemulihan, berapa peluang
diperoleh 3 kartu hati?
N = 52 n = 5 k = 13 x = 3 h(3;52,5,13)=
Rata-Rata dan Ragam bagi Distribusi Hipergeometrik h(x; N, n, k) adalah
. Perluasan Distribusi Hipergeometrik jika terdapat lebih dari 2 kelas
h(x; N, n, k)=
untuk x = 0,1,2,3...,k

13
Distribusi Hipergeometrik dapat diperluas menjadi penyekatan ke dalam beberapa kelas
f=(
dan perhatikan bahwa n= dan N=
N : ukuran populasi atau ruang contoh
n : ukuran contoh acak
k : banyaknya penyekatan atau kelas
xi : banyaknya keberhasilan kelas ke-i dalam contoh
ai : banyaknya keberhasilan kelas ke-i dalam populasi
Contoh 7 :
Dari 10 pengemudi motor, 3 orang mengemudikan motor merk "S", 4 orang memggunakan
motor merk "Y" dan sisanya mengemudikan motor merk "H". Jika secara acak diambil 5 orang,
berapa peluang 1 orang mengemudikan motor merk "S", 2 orang merk "Y" dan 2 orang merk
"H"?
Jawab :
N = 10, n = 5
a1 = 3, a2 = 4, a3= 3
x1 = 1, x2 = 2, x3= 2
Pendekatan Hipergeometrik dapat juga dilakukan untuk menyelesaikan persoalan binomial :
- Binomial R untuk pengambilan contoh dengan pemulihan (dengan pengembalian)
- Hipergeometrik R untuk pengambilan contoh tanpa pemulihan (tanpa pengembalian

14
3. Distribusi Peluang Kontinyu
3.1 Distribusi Normal
Distribusi normal, disebut pula distribusi Gauss, adalah distribusi probabilitas yang
paling banyak digunakan dalam berbagai analisis statistika. Distribusi normal baku adalah
distribusi normal yang memiliki rata-rata nol dan simpangan baku satu. Distribusi ini juga
dijuluki kurva lonceng (bell curve) karena grafik fungsi kepekatan probabilitasnya mirip dengan
bentuk lonceng.
Distribusi normal memodelkan fenomena kuantitatif pada ilmu alam maupun ilmu sosial.
Beragam skor pengujian psikologi dan fenomena fisika seperti jumlah foton dapat dihitung
melalui pendekatan dengan mengikuti distribusi normal. Distribusi normal banyak digunakan
dalam berbagai bidang statistika, misalnya distribusi sampling rata-rata akan mendekati normal,
meski distribusi populasi yang diambil tidak berdistribusi normal. Distribusi normal juga banyak
digunakan dalam berbagai distribusi dalam statistika, dan kebanyakan pengujian hipotesis
mengasumsikan normalitas suatu data.
Distribusi normal pertama kali diperkenalkan oleh Abraham de Moivre dalam artikelnya
pada tahun 1733 sebagai pendekatan distribusi binomial untuk n besar. Karya tersebut
dikembangkan lebih lanjut oleh Pierre Simon de Laplace, dan dikenal sebagai teorema Moivre-
Laplace. Laplace menggunakan distribusi normal untuk analisis galat suatu eksperimen. Metode
kuadrat terkecil diperkenalkan oleh Legendre pada tahun 1805. Sementara itu Gauss mengklaim
telah menggunakan metode tersebut sejak tahun 1794 dengan mengasumsikan galatnya memiliki
distribusi normal.
Istilah kurva lonceng diperkenalkan oleh Jouffret pada tahun 1872 untuk distribusi
normal bivariat. Sementara itu istilah distribusi normal secara terpisah diperkenalkan oleh
Charles S. Peirce, Francis Galton, dan Wilhelm Lexis sekitar tahun 1875. Terminologi ini secara
tidak sengaja memiliki nama sama.

15
Nilai Peluang peubah acak dalamDistribusi Peluang Normal dinyatakan dalam luas dari
di bawah kurva berbentuk genta\lonceng (bell shaped curve).
. Kurva maupun persamaan Normal melibatkan nilai x, ƒÊ dan s.
. Keseluruhan kurva akan bernilai 1, ini mengambarkan sifat peluang yang tidak pernah negatif
dan maksimal bernilai satu
Definisi Distribusi Peluang Normal
N(x;µ,σ)=(1/ ).
untuk nilai x : - < x < e = 2.71828..... p = 3.14159...
µ : rata-rata populasi
σ : simpangan baku populasi
: ragam populasi
Contoh 8 :
Rata-rata upah seorang buruh = $ 8.00 perjam dengan simpangan baku = $ 0.60, jika terdapat 1
000 orang buruh, hitunglah :
a. banyak buruh yang menerima upah/jam kurang dari $ 7.80
b. banyak buruh yang menerima upah/jam lebih dari $ 8.30
c. banyak buruh yang menerima upah/jam antara $ 7.80 sampai 8.30
μ = 8.00 s = 0.60
a. x < 7.80 z=x-µ/σ= 7.80- 8.00/0.60=-0.33
P(x < 7.80) = P(z < -0.33) = 0.5 - 0.1293 = 0.3707
banyak buruh yang menerima upah/jam kurang dari $ 7.80 = 0.3707 x 1 000 = 370.7 = 371 orang
b. x > 8.30
z=x-µ/σ=8.30-8.00/0.60=0.50.

16
P(x > 8.30) = P(z > 0.50) = 0.5 - 0.1915 = 0.3085 (Gambarkan!)
Banyak buruh yang menerima upah/jam lebih dari $ 8.30 = 0.3085 x 1 000
= 308.5 = 309 orang
c. 7.80 < x < 8.30
z1 = -0.33 dan z2 = 0.50
P(7.80 < x < 8.30) = P(-0.33 < z < 0.50) = 0.1915 + 0.1293 = 0.3208 (Gambarkan)
Banyak buruh yang menerima upah/jam dari $ 7.80 sampai $ 8.30 = 0.3208 x 1 000
= 320.8 = 321 orang
• Pendekatan untuk peluang Binomial
p bernilai sangat kecil dan n relatif besar dan
a) JIKA rata-rata (μ) £ 20 MAKA lakukan pendekatan dengan distribusi POISSON dengan
μ = n × p
b) JIKA rata-rata (μ) > 20 MAKA lakukan pendekatan dengan distribusi NORMAL dengan
μ = n × p
s 2 = n × p × q
s = n × p × q
4. Distribusi Sampling
Distribusi sampling, merupakan suatu distribusi teoritis, ini adalah distribusi yang kita
dapatkan jika kita mengambil semua sampel yang mungkin dengan ukuran sama, dari populasi
yang sama, dan yang masing-masing kita tarik secara random. dapat pula hal ini dinyatakan
dengan cara lain : distribusi sampling adalah distribusi, dibawah yang mungkin dijalani oleh
statistik tertentu.
Distibusi sampling suatu statistik menunjukkan kemungkinan kemungkinan di bawah
yang berkaitan dengan berbagai harga angka yang mungkin dari statistik itu. kemungkinan yang

17
berkaitan dengan terjadinya suatu harga tertentu dari statistik itu, dibawah disini digunakan
untuk menunjukkan kemungkina suatu harga tertentu ditambah dengan semua harga yang lebih
ekstrim.
Dengan demikian kemungkinan yang bersangkutan atau kemungkinan yangn berkaitan
dengan kejadian dibawah adalah kemungkinan akan terjadinya suatu harga yang sama
ekstremnya atau lebih ekstrem dari harga tertentu tes statistik dibawah
4.1 Distribusi Sampling Rata-rata
Beberapa notasi :
n : ukuran sampel N : ukuran populasi
x : rata-rata sampel μ : rata-rata populasi
s : standar deviasi sampel σ : standar deviasi populasi
μx: rata-rata antar semua sampel
σx : standar deviasi antar semua sampel = standard error = galat baku
DALIL - 1
JIKA …….
Sampel:
berukuran = n ≥ 30 diambil DENGAN PEMULIHAN dari
rata-rata = x
Populasi berukuran = N
Terdistribusi NORMAL
Rata-rata = μ ; simpangan baku = σ
MAKA………
Distribusi Rata-rata akan mendekati distribusi Normal dengan :
μx= μ dan σx = σ
dan nilai z =
μ
σ

18
DALIL - 2
JIKA …….
Sampel:
berukuran = n ≥ 30 diambil TANPA PEMULIHAN dari
rata-rata = x
Populasi berukuran = N
Terdistribusi NORMAL
Rata-rata = μ ; simpangan baku = σ
MAKA……….
Distribusi Rata-rata akan mendekati distribusi Normal dengan :
μx = μ dan σx = σ
= dan nilai z =
μ
σ
-
disebut sebagai FAKTOR KOREKSI populasi terhingga.
• Faktor Koreksi (FK) akan menjadi penting jika sampel berukuran n diambil dari populasi
berukuran N yang terhingga/ terbatas besarnya
• Jika sampel berukuran n diambil dari populasi berukuran N yang sangat besar maka FK akan
mendekati 1 → NnN−−≈11, hal ini mengantar kita pada dalil ke-3 yaitu :

19
DALIL LIMIT PUSAT = DALIL BATAS TENGAH
( THE CENTRAL LIMIT THEOREM )
• Dalil Limit Pusat berlaku untuk :
1. penarikan sampel dari populasi yang sangat besar,
2. distribusi populasi tidak dipersoalkan
• Beberapa buku mencatat hal berikut : Populasi dianggap BESAR jika ukuran sampel
KURANG DARI 5 % ukuran populasi atau
< 5%
4.2 Distribusi Sampling Rata-rata Sampel Kecil
DISTRIBUSI - t
• Distribusi Sampling didekati dengan distribusi t Student = distribusi t (W.S. Gosset).
Distribusi-t pada prinsipnya adalah pendekatan distribusi sampel kecil dengan distribusi
normal.
Dua hal yang perlu diperhatikan dalam Tabel t adalah
1. derajat bebas (db)
2. nilai α
• Derajat bebas (db) = degree of freedom = v = n - 1.
n : ukuran sampel.
• Nilai α adalah luas daerah kurva di kanan nilai t atau luas daerah kurva di kiri nilai –t
• Nilai α → 0.1 (10%) ; 0.05 (5%) ; 0.025(2.5%) ; 0.01 (1%) ; 0.005(0.5%)
Nilai α terbatas karena banyak kombinasi db yang harus disusun!
DALIL - 3 : DALIL LIMIT PUSAT
JIKA….
Sampel:
berukuran = n diambil dari
rata-rata = x
Populasi berukuran = N yang BESAR
distribusi : SEMBARANG
Rata-rata = μ ; simpangan baku = σ
MAKA…….
Distribusi Rata-rata akan mendekati distribusi Normal dengan :
μx= μ dan σx =
dan nilai z =

20
• Kelak Distribusi t akan kita gunakan dalam PENGUJIAN HIPOTESIS
DALIL - 4
JIKA…
Sampel:
ukuran KECIL n < 30 diambil dari
rata-rata = x simp. baku = s
Populasi berukuran = N
terdistribusi : NORMAL
Rata-rata = μ
MAKA….
Distribusi Rata-rata akan mendekati distribusi-t dengan :
μx= μ dan σx =
dan nilai t =
pada derajat bebas = n-1 dan suatu nilai α
Nilai α ditentukan terlebih dahulu
Lalu nilai t tabel ditentukan dengan menggunakan nilai α dan db.
Nilai t tabel menjadi batas selang pengujian
Lalukan pembandingan nilai t tabel dengan nilai t hitung.
Nilai t hitung untuk kasus distribusi rata-rata sampel kecil didapat dengan menggunakan
DALIL 4

21
5. Pendugaan Parameter
Untuk mengetahui ukuran populasi atau disebut dengan Parameter biasanya seorang peneliti
mengukurnya tidak secara langsung melainkan dengan cara mengambil sebagian kecil dari
populasi (disebut dengan sample) kemudian mengukurnya. Selanjutnya hasil pengukuran sample
tersebut digunakan untuk “menduga” ukuran sebenarnya (ukuran populasinya atau
parameternya). Dari sinilah berasal istilah “Pendugaan Parameter”. Secara umum parameter yang
diduga ialah nilai tengah (mean), proporsi, atau ragam, masing-masing :
- satu nilai tengah
- beda dua nilai tengah populasi
- beda lebih dari dua nilai tengah populasi
- satu proporsi
- beda dua nilai proporsi
- beda lebih dari dua nilai proporsi
- satu ragam
- beda dua nilai ragam
- beda lebih dari dua nilai ragam
Karena nilai parameter tidak bisa ditentukan kepastiannya 100% maka dikenal istilah Selang
Kepercayaan (Confidence Interval) yaitu ukuran yang menunjukan nilai parameter yang asli
mungkin berada. Selang Kepercayaan 95% artinya kita percaya bahwa 95% sample yang kita
ambil akan memuat nilai parameter aslinya. Selang Kepercayaan 99% artinya kita percaya
bahwa 99% sample yang kita ambil akan memuat nilai parameter aslinya.
Selang Kepercayaan (SK) 1 Nilai Tengah
Ragam Diketahui :
Ragam tidak diketahui n<30 :

22
SK Beda 2 Nilai Tengah
Ragam 1 dan Ragam 2 diketahui :
Ragam 1 = Ragam 2 tetapi tidak diketahui :
Ragam 1 tidak sama dengan ragam 2 tetapi tidak diketahui :
SK 1 Proporsi :
SK Beda 2 Proporsi :

23
Ukuran Contoh
Bagi Pendugaan Nilai Tengah :
Bagi Pendugaan Proporsi :
5.1 Sifat-sifat Penduga yang diinginkan :
Takbias : Takbias berarti nilai harapan penduga sama dengan parameter yang diduga.
Penduga x merupakan penduga yang takbias bagi m. Hal ini berarti apabilamproses
penarikan contoh diulang-ulang dan untuk setiap contoh tersebut dihitung x-nya, maka
rata-rata dari tadi akan sama dengan m.
Efisien : Efisiensi penduga ditunjukkan oleh besarnya ragam penduga tersebut. Makin
kecil ragam suatu penduga makin efisien penduga tersebut. Secara teori, di antara
penduga yang takbias, x merupakan penduga dengan ragam paling kecil
Konsisten : Konsisten berarti dengan makin besarnya ukuran contoh maka ragam
penduga makin kecil.

24
6. Uji Chi Kuadrat (χ²)
6.1 Pengertian
Uji Chi Kuadrat adalah pengujian hipotesis mengenai perbandingan antara : frekuensi
observasi/yg benar-benar terjadi/aktual dengan frekuensi harapan/ekspektasi.
Fungsi ini juga merupakan bentuk khusus dari fungsi kepekatan Gamma. Kalau pada peubah acak
Gamma fungsi α dipilih nilai v/2, sedang fungsi v merupakan bilangan bulat positif, serta untuk
nilai β dipilih nilai
Rumus untuk Chi Square :
6.1.1 Frekuensi Observasi dan Frekuensi Harapan
frekuensi observasi → nilainya didapat dari hasil percobaan (o)
frekuensi harapan → nilainya dapat dihitung secara teoritis (e)
Contoh :
1. Sebuah dadu setimbang dilempar sekali (1 kali) berapa nilai ekspektasi sisi-1, sisi-2, sisi-3, sisi-4,
sisi-5 dan sisi-6
muncul?
kategori :
sisi-1 sisi-2 sisi-3 sisi-4 sisi-5 sisi-6
frekuensi
ekspektasi (e)
16 16 16 16 16 16
Apakah data observasi akan sama dengan ekspektasi?
Apakah jika anda melempar dadu 120 kali maka pasti setiap sisi akan muncul sebanyak 20 kali?

25
Coba lempar dadu sebanyak 120 kali, catat hasilnya, berapa frekuensi kemunculan setiap sisi?
6.1.2 Bentuk Distribusi Chi Kuadrat (χ²)
Nilai χ² adalah nilai kuadrat karena itu nilai χ² selalu positif. Bentuk distribusi χ² tergantung dari
derajat bebas(db)/degree of freedom.
Contoh :
- Berapa nilai χ² untuk db = 5 dengan α = 0.010? (15.0863)
- Berapa nilai χ² untuk db = 17 dengan α = 0.005? (35.7185)
Pengertian α pada Uji χ² sama dengan pengujian hipotesis yang lain, yaitu luas daerah penolakan H0
atau taraf nyata pengujian
6.2 Pengunaan Uji Chi Kuadrat (χ² )
Uji χ² dapat digunakan untuk :
a. Uji Kecocokan = Uji kebaikan-suai = Goodness of fit test
b. Uji Kebebasan
c. Uji beberapa proporsi
Prinsip pengerjaan (b) dan (c) sama saja
Dalam referensi lain menybeutkan juga penggunaan uji chi kuadrat sebagai berikut :
1. Ada tidaknya asosiasi antara 2 variabel (Independent test)
2. Apakah suatu kelompok homogen atau tidak (Homogenity test)
3. Uji kenormalan data dengan melihat distribusi data (Goodness of fit test)

26
7. Hipotesis
7.1 Pengertian Hipotesis
Berdasarkan etimologinya hipotesis berasal dari dua suku kata, hipo; yang berarti
lemah dan tesis; yang berarti pernyataan. Bila digabung berarti menjadi pernyataan yang
masih lemah. Akan tetapi dalam jangkauan yang lebih luas, misalnya untuk kepentingan-
kepentingan penelitian, maka hipotesis dapat didefinisikan sebagai dugaan sementara yang
diajukan seorang peneliti untuk diuji kebenarannya.
Hipotesis statistik yang selanjutnya akan dinyatakan hipotesis, didefinisikan sebagai
pernyataan matematis tentang karakteristik populasi yang ditinjau, yang akan diuji atau
dipelajari sejauh mana suatu data atau sampel merupakan suatu himpunan bagian dari
populasi, tidaklah pantas jika dipakai pernyataan, “hipotesis akan dibuktikan kebenarannya
dengan memakai hanya sebuah data sampel”. apalagi jika sampel yang dipakai tidak benar-
benar sampel yang random. Karena yang diuji kebenarannya melalui statistik didalam
penelitian adalah hipotesis nihil atau , sedangkan yang disebut hipotesis kerja atau
merupakan pernyataan yang menyatakan adanya perbedaan atau hubungan antara dua
variabel atau lebih.
Secara umum dapat dikemukakan bahwa seorang peneliti akan mengemukakan hanya
salah satu dari ke-enam alternatif hipotesis statistik yang mungkin, yang secara statistik dapat
ditulis sebagai berikut :
A. Hipotesis Dua Pihak :
: θ = θ
: θ ≠ θ
B. Hipotesis Sepihak (pihak kanan)
: θ ≤ θ
: θ > θ
C. Hipotesis Sepihak (pihak kiri)
: θ ≥ θ
: θ < θ
dimana θ menyatakan nilai suatu parameter populasi, seperti proporsi, rata-rata, varian,
koefisien, korelasi dan sebagainya , dan θ menyatakan sebuah nilai tertentu yang
didefinisikan oleh peneliti.
Dalam penelitian hanya ada satu hipotesis yang benar, yaitu hipotesis yang terbukti saja.
Pembuktian penerimaan hipotesis ini ditunjukkan oleh tingkat atau taraf signifikansi hasil uji
statistik yang diperoleh dalam penelitian. Apabila hipotesis kerja diterima maka hipotesis
nihil ditolak, begitu juga sebaliknya. Pada taraf signifikansi yang berbeda hipotesis kerja dan

27
nihil dapat secara bersama-sama diterima apabila kedua taraf signifikansi tersebut hasil
statistiknya bermakna, dan sebaliknya.
7.2 PENGUJIAN HIPOTESIS
Pengujian hipotesis berhubungan dengan penerimaan atau penolakan suatu hipotesis.
Kebenaran (benar atau salahnya ) suatu hipotesis tidak akan pernah diketahui dengan pasti,
kecuali kita memeriksa seluruh populasi. (Memeriksa seluruh populasi? Apa mungkin?)
Lalu apa yang kita lakukan, jika kita tidak mungkin memeriksa seluruh populasi untuk
memastikan kebenaran suatu hipotesis?
Kita dapat mengambil contoh acak, dan menggunakan informasi (atau bukti) dari contoh itu
untuk menerima atau menolak suatu hipotesis.
Penerimaan suatu hipotesis terjadi karena TIDAK CUKUP BUKTI untuk MENOLAK hipotesis
tersebut dan BUKAN karena HIPOTESIS ITU BENAR
dan
Penolakan suatu hipotesis terjadi karena TIDAK CUKUP BUKTI untuk MENERIMA hipotesis
tersebut dan BUKAN karena HIPOTESIS ITU SALAH.
Landasan penerimaan dan penolakan hipotesis seperti ini, yang menyebabkan para
statistikawan atau peneliti mengawali pekerjaan dengan terlebih dahulu membuat hipotesis
yang diharapkan ditolak, tetapi dapat membuktikan bahwa pendapatnya dapat diterima.
Perhatikan contoh-contoh berikut :
Contoh 9 :

28
Sebelum tahun 1993, pendaftaran mahasiswa Universtas GD dilakukan dengan pengisian
formulir secara manual. Pada tahun 1993, PSA Universitas GD memperkenalkan sistem
pendaftaran "ON-LINE". Seorang Staf PSA ingin membuktikan pendapatnya “bahwa rata-rata
waktu pendaftaran dengan sistem ON-LINE akan lebih cepat dibanding dengan sistem yang
lama” Untuk membuktikan pendapatnya, ia akan membuat hipotesis awal, sebagai berikut :
Hipotesis Awal : rata-rata waktu pendaftaran SISTEM "ON-LINE" sama saja dengan SISTEM
LAMA.
Staf PSA tersebut akan mengambil contoh dan berharap hipotesis awal ini ditolak, sehingga
pendapatnya dapat diterima!
Contoh 10 :
Manajemen PERUMKA mulai tahun 1992, melakukan pemeriksaan karcis KRL lebih intensif
dibanding tahun-tahun sebelumnya, pemeriksaan karcis yang intensif berpengaruh positif
terhadap penerimaan PERUMKA. Untuk membuktikan pendapat ini, hipotesis awal yang
diajukan adalah :
Hipotesis Awal :TIDAK ADA PERBEDAAN penerimaan SESUDAH maupun SEBELUM
dilakukan perubahan sistem pemeriksaan karcis. Manajemen berharap hipotesis ini ditolak,
sehingga membuktikan bahwa pendapat mereka benar!
Hipotesis Awal yang diharap akan ditolak disebut : Hipotesis Nol (H0 )
Penolakan H0 membawa kita pada penerimaan Hipotesis Alternatif ( H1) (beberapa buku
menulisnya sebagai HA )
Nilai Hipotesis Nol ( H0 ) harus menyatakan dengan pasti nilai parameter.
H0 ditulis dalam bentuk persamaan
Sedangkan Nilai Hipotesis Alternatif ( H1 ) dapat memiliki beberapa kemungkinan.
H1 ditulis dalam bentuk pertidaksamaan (< ; > ; )
Contoh 11.(lihat Contoh 9) :

29
Pada sistem lama, rata-rata waktu pendaftaran adalah 50 menit Kita akan menguji pendapat
Staf PSA tersebut, maka
Hipotesis awal dan Alternatif yang dapat kita buat :
H0 : = 50 menit (sistem baru dan sistem lama tidak berbeda)
H1 : 50 menit (sistem baru tidak sama dengan sistem lama)
atau
H0 : = 50 menit (sistem baru sama dengan sistem lama)
H1 : < 50 menit ( sistem baru lebih cepat)
Contoh 12 (lihat Contoh 10) :
Penerimaan PERUMKA per tahun sebelum intensifikasi pemeriksaan karcis dilakukan = Rp. 3
juta. Maka Hipotesis Awal dan Hipotesis Alternatif dapat disusun sebagai berikut:
H0 : = 3 juta (sistem baru dan sistem lama tidak berbeda)
H1 : 3 juta (sistem baru tidak sama dengan sistem lama)
atau
H0 : = 3 juta (sistem baru dan sistem lama tidak berbeda)
H1 : > 3 juta (sistem baru menyebabkan penerimaan per tahun lebih besar
dibanding sistem lama)
Penolakan atau Penerimaan Hipotesis dapat membawa kita pada 2 jenis kesalahan
(kesalahan= error = galat), yaitu :
1. Galat Jenis 1 Penolakan Hipotesis Nol ( H0 ) yang benar

30
Galat Jenis 1 dinotasikan sebagai
juga disebut taraf nyata uji
Catatan : konsep dalam Pengujian Hipotesis sama dengan konsep konsep pada
Selang Kepercayaan
2. Galat Jenis 2 Penerimaan Hipotesis Nol ( H0 ) yang salah
Galat Jenis 2 dinotasikan sebagai
Prinsip pengujian hipotesis yang baik adalah meminimalkan nilai dan
Dalam perhitungan, nilai dapat dihitung sedangkan nilai hanya bisa dihitung jika nilai
hipotesis alternatif sangat spesifik.
Pada pengujian hipotesis, kita lebih sering berhubungan dengan nilai . Dengan asumsi, nilai
yang kecil juga mencerminkan nilai yang juga kecil.
Catatan : keterangan terperinci mengenai nilai dan , dapat anda temukan dalam bab 10,
Pengantar Statistika, R. E. Walpole)
Dapat disimpulkan:
Prinsip pengujian hipotesa adalah perbandingan nilai statistik uji (z hitung atau t hitung)
dengan nilai titik kritis (Nilai z tabel atau t Tabel)
Titik Kritis adalah nilai yang menjadi batas daerah penerimaan dan penolakan hipotesis.
Nilai pada z atau t tergantung dari arah pengujian yang dilakukan.
7.2.1 Arah Pengujian Hipotesis
Pengujian Hipotesis dapat dilakukan secara : A. Uji Satu Arah
B. Uji Dua Arah
31
A. Uji Satu Arah
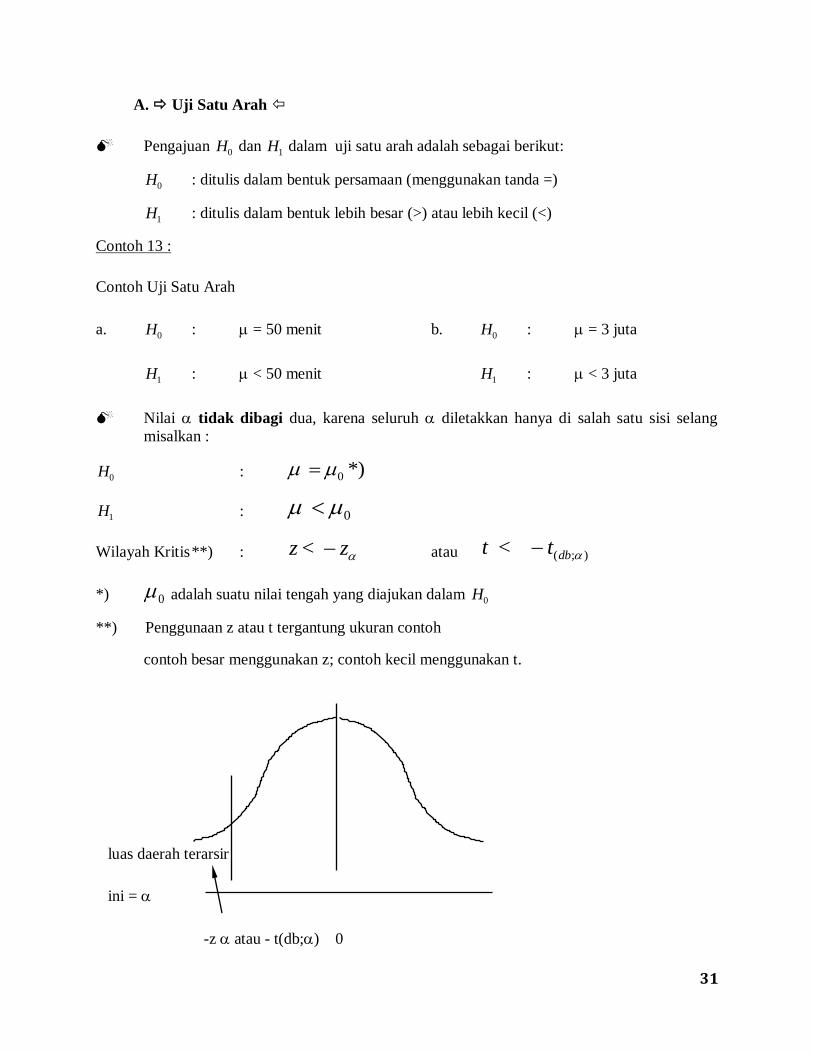
Pengajuan H0 dan H1 dalam uji satu arah adalah sebagai berikut:
H0 : ditulis dalam bentuk persamaan (menggunakan tanda =)
H1 : ditulis dalam bentuk lebih besar (>) atau lebih kecil (<)
Contoh 13 :
Contoh Uji Satu Arah
a. H0 : = 50 menit b. H0 : = 3 juta
H1 : < 50 menit H1 : < 3 juta
Nilai tidak dibagi dua, karena seluruh diletakkan hanya di salah satu sisi selang
misalkan :
H0 : *) 0
H1 : 0
Wilayah Kritis **) : z z < atau t t db < ( ; )
*) 0 adalah suatu nilai tengah yang diajukan dalam H0
**) Penggunaan z atau t tergantung ukuran contoh
contoh besar menggunakan z; contoh kecil menggunakan t.
luas daerah terarsir
ini =
-z atau - t(db;) 0
32
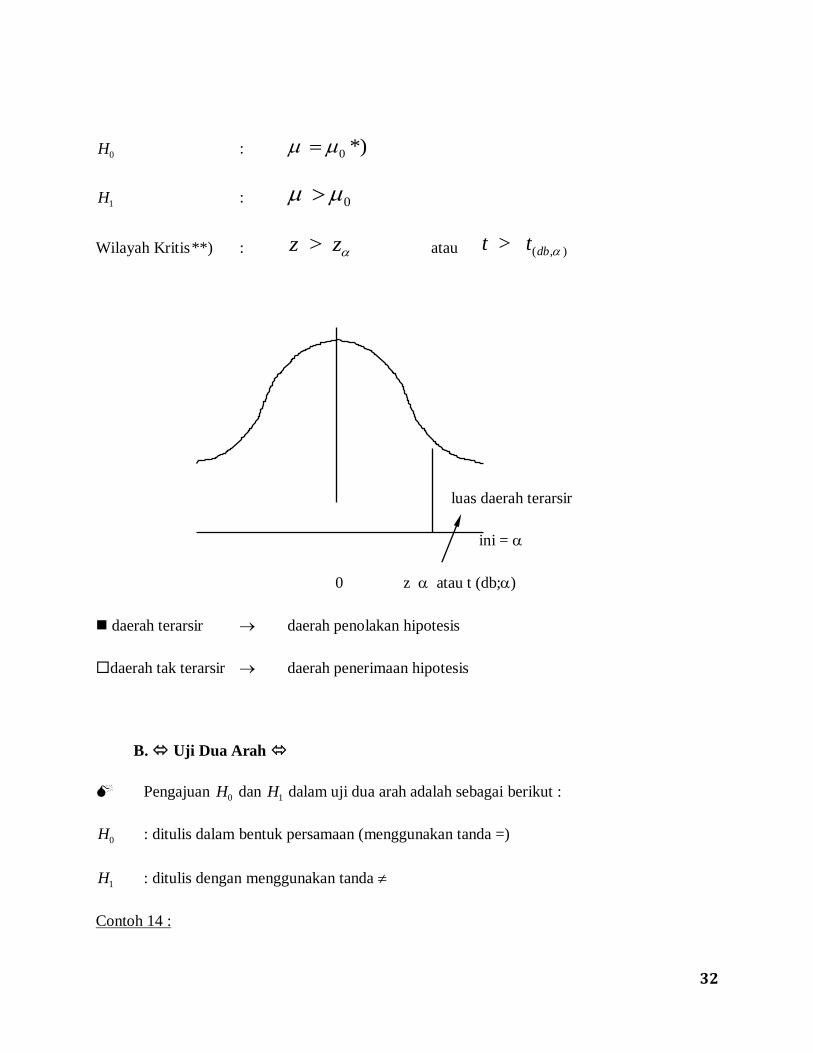
H0 : *) 0
H1 : 0
Wilayah Kritis **) : z z > atau t t db > ) ( ,
luas daerah terarsir
ini =
0 z atau t (db;)
daerah terarsir daerah penolakan hipotesis
daerah tak terarsir daerah penerimaan hipotesis
B. Uji Dua Arah
Pengajuan H0 dan H1 dalam uji dua arah adalah sebagai berikut :
H0 : ditulis dalam bentuk persamaan (menggunakan tanda =)
H1 : ditulis dengan menggunakan tanda
Contoh 14 :
33
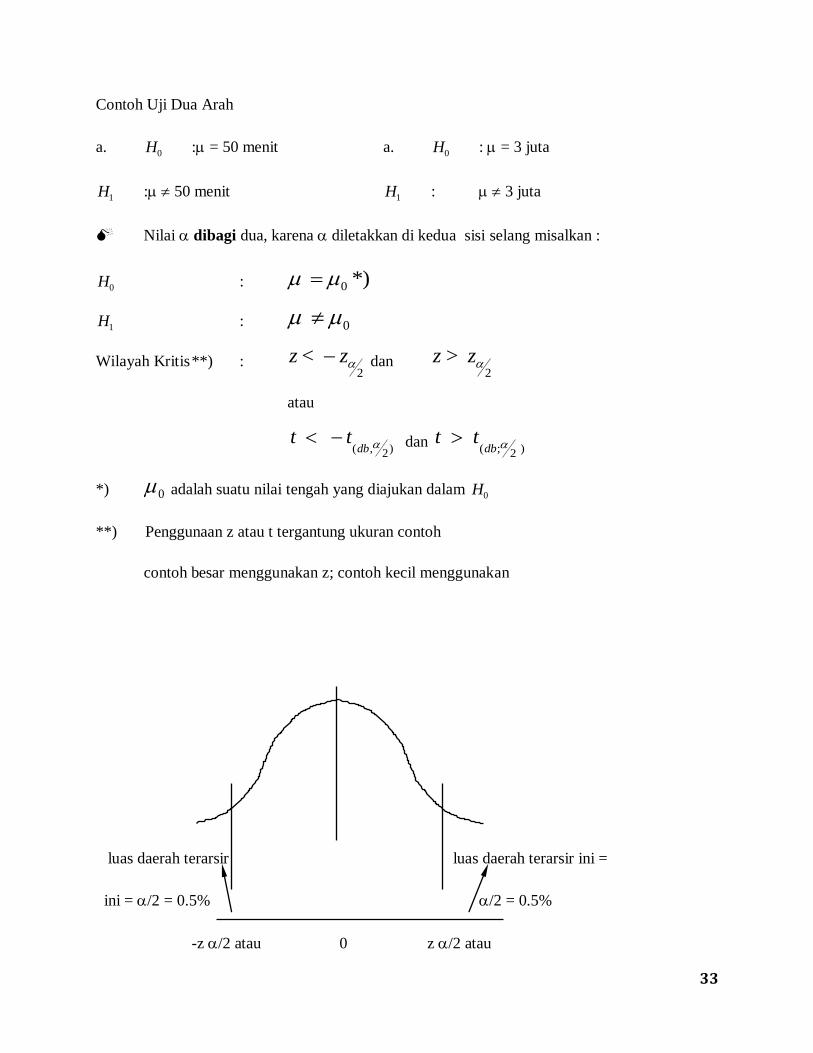
Contoh Uji Dua Arah
a. H0 : = 50 menit a. H0 : = 3 juta
H1 : 50 menit H1 : 3 juta
Nilai dibagi dua, karena diletakkan di kedua sisi selang misalkan :
H0 : *) 0
H1 : 0
Wilayah Kritis **) : z z < 2
dan z z > 2
atau
t tdb
)
( , 2
dan t tdb
)
( ; 2
*) 0 adalah suatu nilai tengah yang diajukan dalam H0
**) Penggunaan z atau t tergantung ukuran contoh
contoh besar menggunakan z; contoh kecil menggunakan
luas daerah terarsir luas daerah terarsir ini =
ini = /2 = 0.5% /2 = 0.5%
-z /2 atau 0 z /2 atau

34
-t(db;/2) t(db;/2)
daerah terarsir daerah penolakan hipotesis
daerah tak terarsir daerah penerimaan hipotesis
7.3 Pengerjaan Uji Hipotesis.
7 Langkah Pengerjaan Uji Hipotesis :
1. Tentukan H0 dan H1
2* Tentukan statistik uji [ z atau t]
3* Tentukan arah pengujian [1 atau 2]
4* Taraf Nyata Pengujian [ atau /2]
5. Tentukan nilai titik kritis atau daerah penerimaan-penolakan H0
6. Cari nilai Statistik Hitung
7. Tentukan Kesimpulan [terima atau tolak H0 ]
*) Urutan pengerjaan langkah ke2, 3 dan 4 dapat saling dipertukarkan!
Beberapa Nilai z yang penting
z z5% 0 05 . =1.645 z z2 5% 0 025. . =1.96
z z1% 0 01 . = 2.33 z z0 5% 0 005. . = 2.575
7.3.1 Rumus-rumus Penghitungan Statistik Uji
1. Nilai Tengah dari Contoh Besar
2. Nilai Tengah dari Contoh Kecil
3. Beda 2 Nilai Tengah dari Contoh Besar
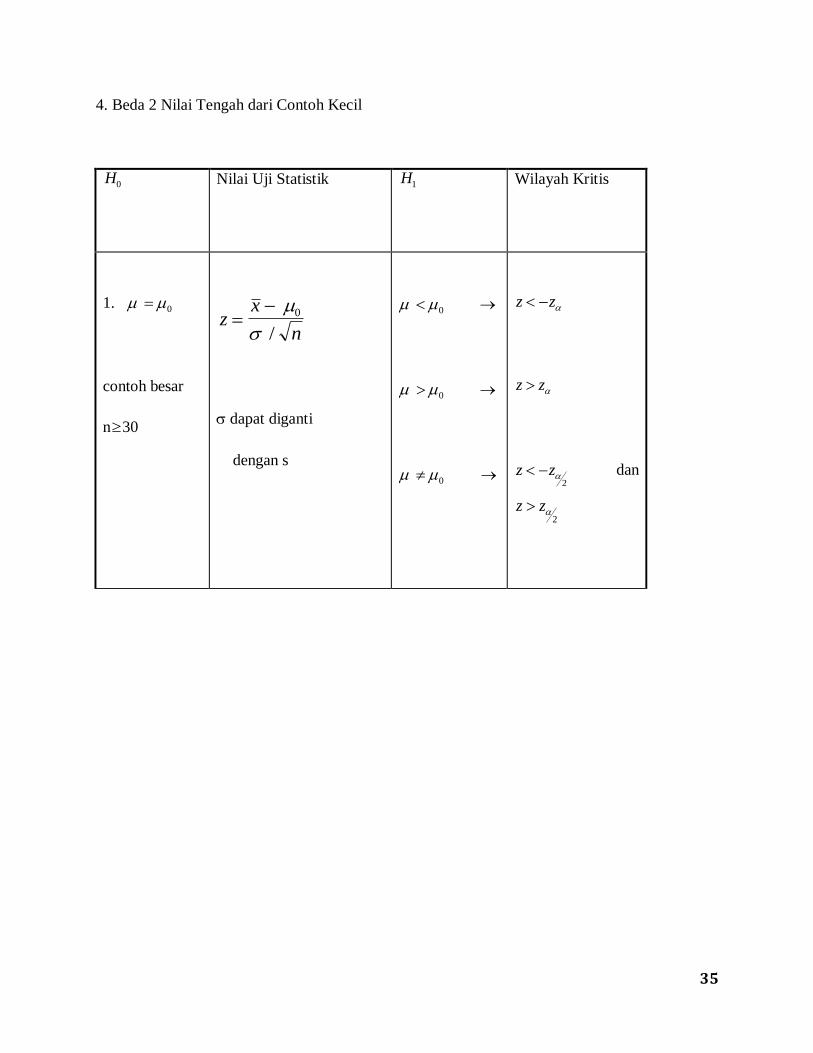
35
4. Beda 2 Nilai Tengah dari Contoh Kecil
H0 Nilai Uji Statistik
H1 Wilayah Kritis
1. 0
contoh besar
n30
zx
n
0
/
dapat diganti
dengan s
0
0
0
z z
z z
z z 2
dan
z z 2

36
2. 0
contoh kecil
n<30
ns
xt
/
0
0
0
0
t t db < ( ; )
t t db > ) ( ,
t tdb
)
( , 2
dan
t tdb
)
( ; 2
db = n-1
3. 1 2 0 d
contoh-contoh
besar
n1 30
n2 30
zx x d
n n
1 2 0
1
2
1 2
2
2
( / ) ( / )
Jika 1
2 dan 2
2 tidak
diketahui gunakan s1
2
dan s2
2
1 2 0 d
1 2 0 d
1 2 0 d
z z
z z
z z 2
dan
z z 2

37
4.
1 2 0 d
contoh -contoh
kecil
n1< 30
n2 < 30
tx x d
s n s n
1 2 0
1
2
1 2
2
2
( / ) ( / )
1 2 0 d
1 2 0 d
1 2 0 d
t t
t t
t tdb
)
( , 2
dan
t tdb
)
( ; 2
db = n n1 2 2

38
DAFTAR PUSTAKA
Agung, I Gusti Ngurah. 2004. Statistika : penerapan metode analisis untuk tabulasi sempurna
dan tak sempurna, PT Raja Grafindo Persada. Jakarta
Nasoetion, A.H. 1983. Teori Statistika. Edisi ke dua, Bhratara. Jakarta
Modul
Gunarto, T.Y. 2000. Distribusi Sampling. Universitas Gunadarma. Jakarta